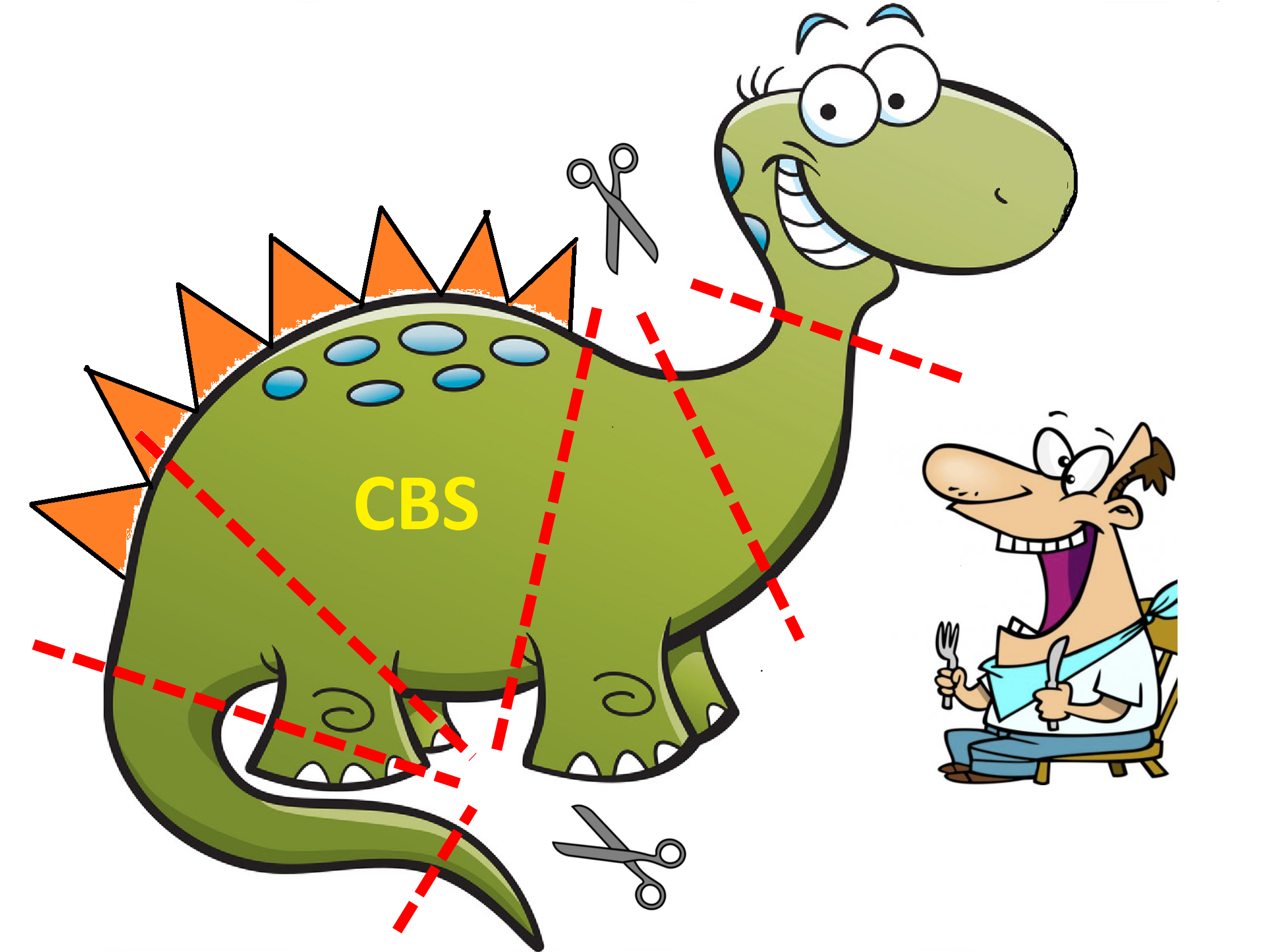
I got a question from a colleague about how I would approach the replacement of an aging core banking system (CBS). Although I had an encounter with a project of this kind earlier, I wanted to give a more elaborate answer so I got in touch with a few silverback CIOs of the local IT community who had a first-hand experience with these beasts. (I express my appreciation for your help, Guys!)
This post is a summary of the interviews I had with IT executives in the CEE region mixed with my own observations. I dare to say that most of the suggestions below stay true for telco billing systems, or any major endeavor that touches the core functions of the firm and has interfaces with large number of other systems. So here we go:
- Start with the why – if these reasons are not shared by the top management – do not start the whole thing. The best analogy to a CBS replacement is changing the engine of an aircraft during flight: this is the last thing you want to do since it will bog you down for 5+ years, will cost your proverbial shirt and nobody can guarantee that it will succeed. You must have a well understood, easy to communicate reason why you do this and you have to have the commitment from the board to support your venture sworn by blood. (They might forget about their oath in two years...)
- This is NOT an IT project rather a process / product level overhaul of the ship with a significant technology support. (to prove my point check out the Standish CHAOS reports or the various lists of the biggest flops in IT – technology itself IS NOT in the primary reason for a failure in most cases. Unrealistic changes driven by politics is a bigger danger.)
- Chose the right time – “When the moon is in the Seventh House and Jupiter aligns with Mars”, ie. when the ownership and management structure of the firm is stable, the economic environment is fine and the regulators are a relaxed and not introducing major legislations that demand immediate action.
- The sponsor and his/her relationship to the PM – you are not tinkering with a pimple on your chin, this is heart surgery! As historical records show those projects achieved their business goal where the PM had the unwavering trust of the CEO ie. the head of the program is not a CIO direct but a CEO direct. (the CIO would qualify but is usually busy running IT as we know it.)
- Keep the ten commandments – DO NOT allow any customization in the core or live with the consequences: There is a theory by Gartner called the Pace layered IT architecture. In a single sentence: Tinker with the application layer where your competitive advantage actually lays (system of innovation) and DO NOT mess up the lower layers, especially the system of records. I guess the 11th commandment that the business keeps scarifying for short term gains is “Thou shalt not build frequently changing business functions into the foundation of your institution”. (The 12th is “Thou shalt not create point to point interfaces”. Well, they are as problematic to keep as “Thou shalt not covet thy neighbour's wife.”
- KYD – Know Your Dinosaur – some of these systems linger around for 20+ years, carrying a thick guano of poorly documented changes, with the original developers gone for years by the time your great adventure starts. This is reverse engineering time when the project team tries to understand the process from the code. It will take time.
- Make your Dino more simple - Remove any functionality that does not belong to the core feature set. This is undoing the sins of the past (when eg. you built OLTP functions in your data warehouse or baked the deposit management of a loan into the a/c handling system itself.) Of course when you create a centralized client master data management solution, you will have to create an interface to the master data management in the new system. (do not allow multi-master solutions.)
- Staffing – The teams of these projects can grow substantial (up to 150 people). These folks are the ones with the deepest knowledge about your existing processes and systems whom you take away from their day jobs and who will be greatly missed by their line managers. It makes sense to set up a formal process to regulate this exodus of talent from the daily business and to reach out to system integrators or local partners of the COTS vendor to fill the gap.
A guaranteed source of conflict is when the annual resource planning exercise ASSUMES that these jolly jokers are still in their regular positions and assigns tasks to them. The business will attest that the Earth will stop spinning without these folks and will reclaim them. This is when deadlines start vanishing. A potential way to avoid this conflict to ask for dedicated people and even to create a dedicated org unit for the project. - Coexistence – Life will not stop for the years while you are building the “Great New Thing” The owners of current systems will keep churning out new releases, will modify interfaces or even change the underlying data structures. For this reason, this is vital to capture these changes and to make sure that you have the latest version of all corresponding systems in your test environment. You need to automate – on top of automating the testing of the new system itself - the buildup of an integrated test environment, including test creation of the test data.
- Evolution vs. Revolution - i got the feedback from a ex colleague of mine that I i missed an aspect, namely that you have to produce something on a regular basis that the business actually can use. This keeps the hope alive that you are moving to the right direction and gives the chance to the client to provide feedback.
- Test data – Gary Larson mentions a separate chamber in Hell for those who drive slow in the fast lane. I think there is another bucket for those who invented GDPR. Imagine building a test scenario where all systems depersonalize their master data on their own right. You may want to be a bit more forgiving when enforcing those GDPR guidelines… (25+ years ago lawmakers in Hungary abolished the use of the personal ID since it could allow those nasty IT people to link disjunct databases. So the industry went back and used strings instead (name, mother’s name, address etc. UNTIL the government really wanted to identify you and asked to enter your social security number and your tax ID for mostly anything (the two together are as good as the personal ID was). I think that the fact that the whole society is self-profiling itself in social media for poo emojis will cause an even bigger trouble and lawmakers are lukewarm at best to stop it.

- The interfaces –the Achilles heel of any complex IT project. A CBS can have 50+ interfaces, using technologies invented by your ancestors. You set a goal to replace these not so secure interfaces with something modern (for the record: ITSec hold you at gunpoint to do it.) The issue: it requires changes in the other systems by those people whom you just brought over to your project. Oops.. Ok, you decide to EMULATE the old interfaces to the outside world while going super doper inside. Things start to go ugly so you obtain the first permission to fall back on the old solutions, “just temporarily”. For the record: temporary solutions will stay for 10+ years. The business will never allow you to spend money replacing them!
- Close coupling – this is the fancy name for not using API-s and eg. suck out data directly from the database of another system. This is cool until they change the DB layout… If there is a place in life for enterprise architects then this is guarding the adherence to design best practices regarding interfaces.

- The vendor – vendors love when you are on the hook. It is like a thick needle in your vein, pumping your money into their pockets, and you just cannot escape. As long as they are good at what they do this might be acceptable. They will be nice during the courting phase but the gloves may come off when the first non-acceptance occurs. It makes sense to have escape clauses for both parties with well-defined milestones.
It is also important to note that all the promises made by the vendor about the new functions rolled out on a regular basis – paid in the annual maintenance and support fee – WILL NOT be available to you once you started to customize the base offering. (This applies only when you go for a commercial off-the-shelf solution.) - The system integrator – as mentioned earlier in the staffing section you are likely to run short on skilled people, so you are likely to turn to a system integrator for help. The issue is when you get an army of rookies instead of the highly skilled folks you met during the presales phase OR when you realize nuances like a kickback from a certain HW vendor. Make sure you really understand the business model of your provider and accept the fact that good people are expensive. A theoretical alternative is to solely rely upon your own internal project team, but the recruitment and ramp up hurdle makes it challenging.
- 24 x 7 – in the era of instant gratification people just cannot live without an always on banking service. This requires your new system to be able to work without the old daily closure when you had to maintain a shadow balance since the CBS was busy with its closure batch processing.
- A word on HW: Do not start with buying a bunch of iron and licenses, use a public cloud offering and a bare minimum of licenses until you are done with the process related issues. Consider not buying HW at all, but staying on a public cloud throughout the whole project and moving back only at the end if necessary.
- A word on SW: Make sure that your new CBS (auto) scales out rather than scaling up. Most managers are familiar with the concept of containers and micro services but some of them do not realize that this capability is only enabled by the underlying platform and the application layer itself will have to take advantage of these capabilities.
The not so PC stuff
- Beware of Conway’s law – some financial institutions have more than one core banking system operated by separate silos. To avoid never ending turf wars it makes sense to consider moving the various a/c handling systems into the same org unit. As Melvin Conway put it: “Any organization that designs a system will produce a design whose structure is a copy of the organization's communication structure.” (Read: a copy of its org chart) If the management decides to do a major reorg, they should do it well before the project starts since it takes 6+ months after such events until functions, competencies and accountabilities will be aligned again.
- The location of the vendor team – “It will be done by next Monday” means a different thing in Europe vs. in other parts of the Globe. Chances are that your dev team will be located in India so you need to get accustomed to the cultural differences.
- Occupational hazard of the PM - if something goes wrong with a large scale undertaking the upper management will seek for a scapegoat, that is most likely the PM. This is business as usual as long as you negotiated a decent severance package in advance.

My interviewees highlighted that they were only scratching the surface during our discussions. I hope that you enjoyed reading it. As always I will be happy to hear from you on this topic.

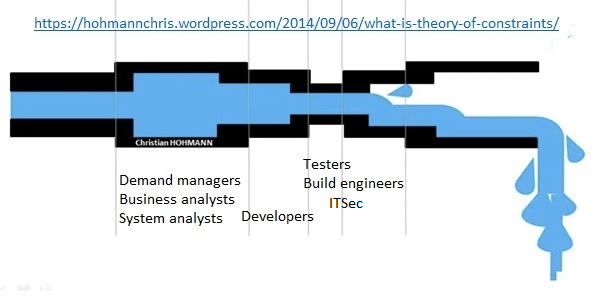





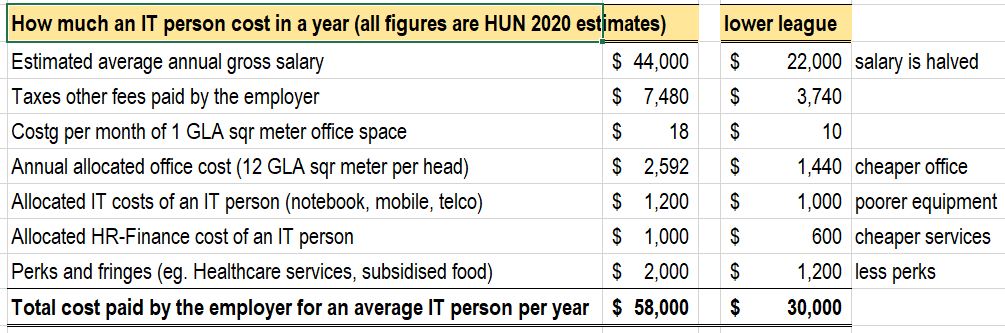




 The following post is about the pitfalls of creating a private cloud. My aim is to list some the potential pitfalls down the road implementing a private cloud, and not to take away your ambition. This is the opposite: You are running against time. Once the regulatory environment (in CEE) lifts the restrictions on the usage of offerings from public cloud providers, you are going to face a formidable competition with offerings being honed for ten plus years. You have to find niches where you can beat them before this change happens. So here we go:
The following post is about the pitfalls of creating a private cloud. My aim is to list some the potential pitfalls down the road implementing a private cloud, and not to take away your ambition. This is the opposite: You are running against time. Once the regulatory environment (in CEE) lifts the restrictions on the usage of offerings from public cloud providers, you are going to face a formidable competition with offerings being honed for ten plus years. You have to find niches where you can beat them before this change happens. So here we go: