It seems that the law of supply and demand doesn’t work the usual way in the cloud related job market: It creates behavioural distortions rather than the gradual move to a healthy equilibrium. While key players seemingly declared victory and shifted their sight to the next battlefield of AI, this anomaly, combined with the heightened scrutiny from the regulators might hurt adoption in the long run. This post aims to identify the root cause and to suggest possible ways out of this problem.
Symptoms - What’s going on here?
I have been tinkering with cloud implementations for several years. It baffled me that – despite of the cloud-dev(sec)ops engineer compensation being 30+ % above the average - the inflow of talent into this area is far lower than anticipated.
The salary structure for an individual contributor DevSecOps Engineer varies based on geolocation, level of experience, and company size. Below is a table outlining the approximate salary ranges for different levels in various regions:

- For the above reason my team lost 10+ top notch cloud/devops engineers in two years. Most of these folks went abroad, one of them as far as Vancouver. Some others stayed in their homes but switched to foreign employers.
- Some contractors sold 80% of their time twice, to two different customers, one of them was so unashamed that he put his other job in his Linkedin profile. (There are telltale signs of this behaviour: insisting on full home office and missing regular meetings, later deadlines.) Some elevated this practice to the company level…
- Some others played a fair game and told upfront that they work for multiple clients, carried 3 (!) notebooks (one for each client plus one for their own company, God bless virtual desktops…) and declared that they would not even pick up the phone on days assigned to their other clients.
- The cloud IT market bears resemblance to the construction industry, two, sometimes three layers of subcontractors adding little value besides their margin to the price tag.
The root cause
The wheel reinvented: this is the imbalance between supply and demand. The thing that bugged me was that despite of knowing the impressive earning potential, less than one percent of the internal IT Operations workforce (in a HUN commercial bank) made a substantial effort to learn the new discipline. (Those who did soon left ITOps.) On the other side of the house few developers made a career shift to become DevOps/IaC experts.
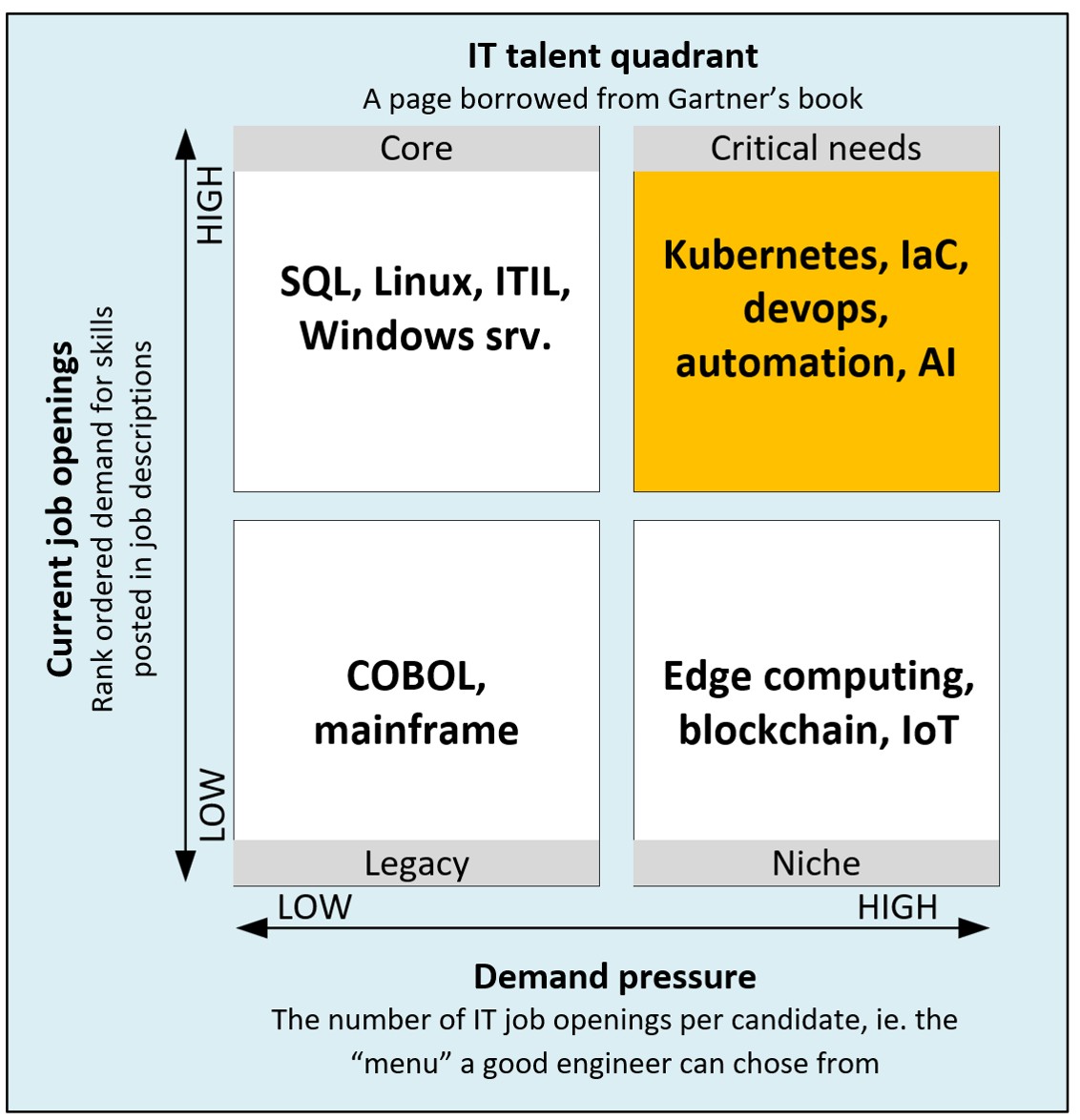
Gartner found a good demonstration of the problem in 2021. They dubbed it IT Talent quadrant. This matrix uses the stack ranked demand (the number of job postings asking for a given skill) vs. the number of these job openings per candidate as dimensions and provides evidence that Kubernetes, Infrastructure as a Code and Automation are critical ingredients for any cloud implementation. For some reason Gartner did not update this chart since 2021.
I created my own explanation, the Commitment matrix, that uses the seller’s commitment to his/her employer vs. the buyer’s commitment to its employee as dimensions. (In some cases, the seller and the employee being the same.)
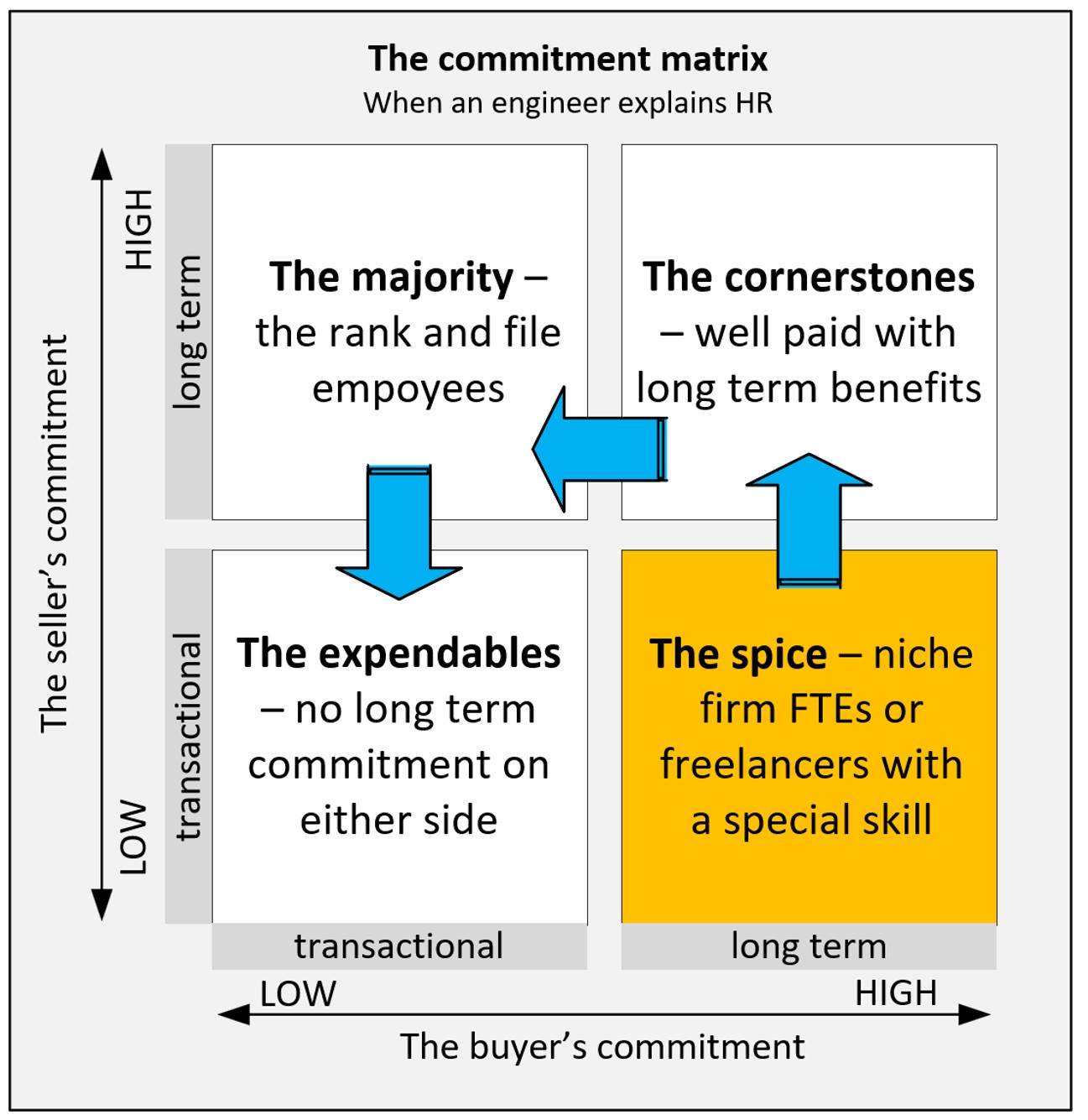
In most cases there is a gradual shift of any new skill from being a Spice to a Cornerstone and later to drift into the Majority. For some reason in case of the most wanted cloud expertise this shift is just not happening.
The reasons
- the cloud is an expanding universe, more and more large companies make their inroads, thus generating new demand for experienced people.
- Buyers would love to have Spice people on their staff, but are not willing to pay the requested premium, claiming that it would generate internal salary tensions. (or simply drawing the comp. ceiling too low.) On the other hand, the very same corporations are willing to pay twice as much for the same people as contractors.
- Top engineers do not want to work for a large firm as rank and file, they pledge allegiance to their boutique consulting firms instead. Smaller size means a more direct connection of the person’ contribution to the performance of the firm, thus results in perks up to partial ownership, let alone being among great technical peers is a nirvana for an engineer.
- Achieving Spice level requires extensive learning and practice. Let alone the industry dictates a breakneck speed: your knowledge will become obsolete within 4-5 years unless you keep updating it. Cloud DevOps and Security are good examples for the Pi shaped skillset. One needs to understand the traditional development principles like branching or a pull request (and must write decent code) while being familiar with the nitty-gritty of name resolution in a hybrid environment with private endpoints or how a policy set will interact with the underlying Terraform codebase.
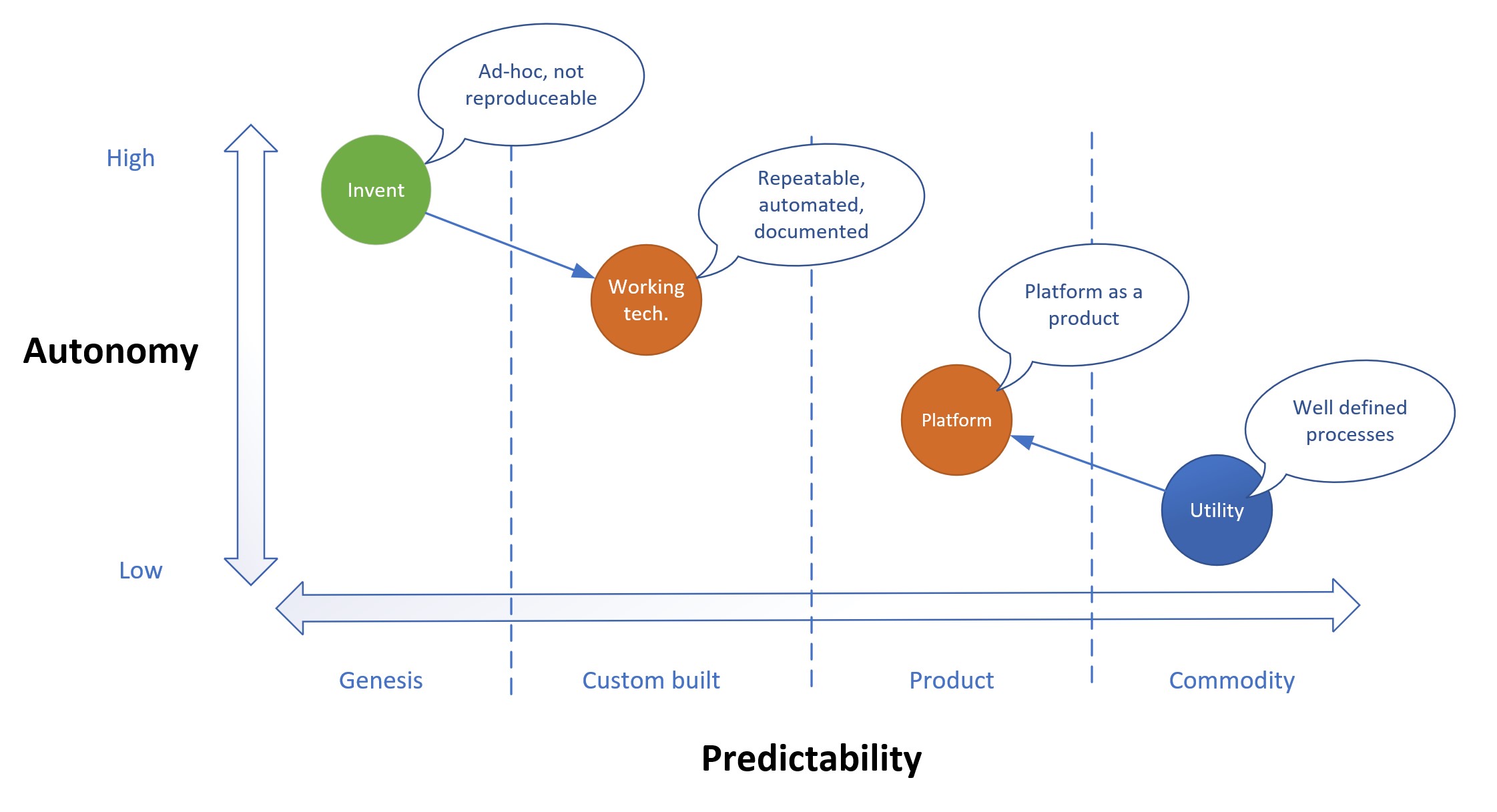
- The last item could come from etymology: Dev + Ops is like mixing oil with water. Development is akin to creating something new, thus experimenting with the unknown: little predictability with high level of autonomy. Operations on the other side hinge on high level of predictability and minimal autonomy. I already used the modified Wardley map to depict this divide, but it is worth repeating it.
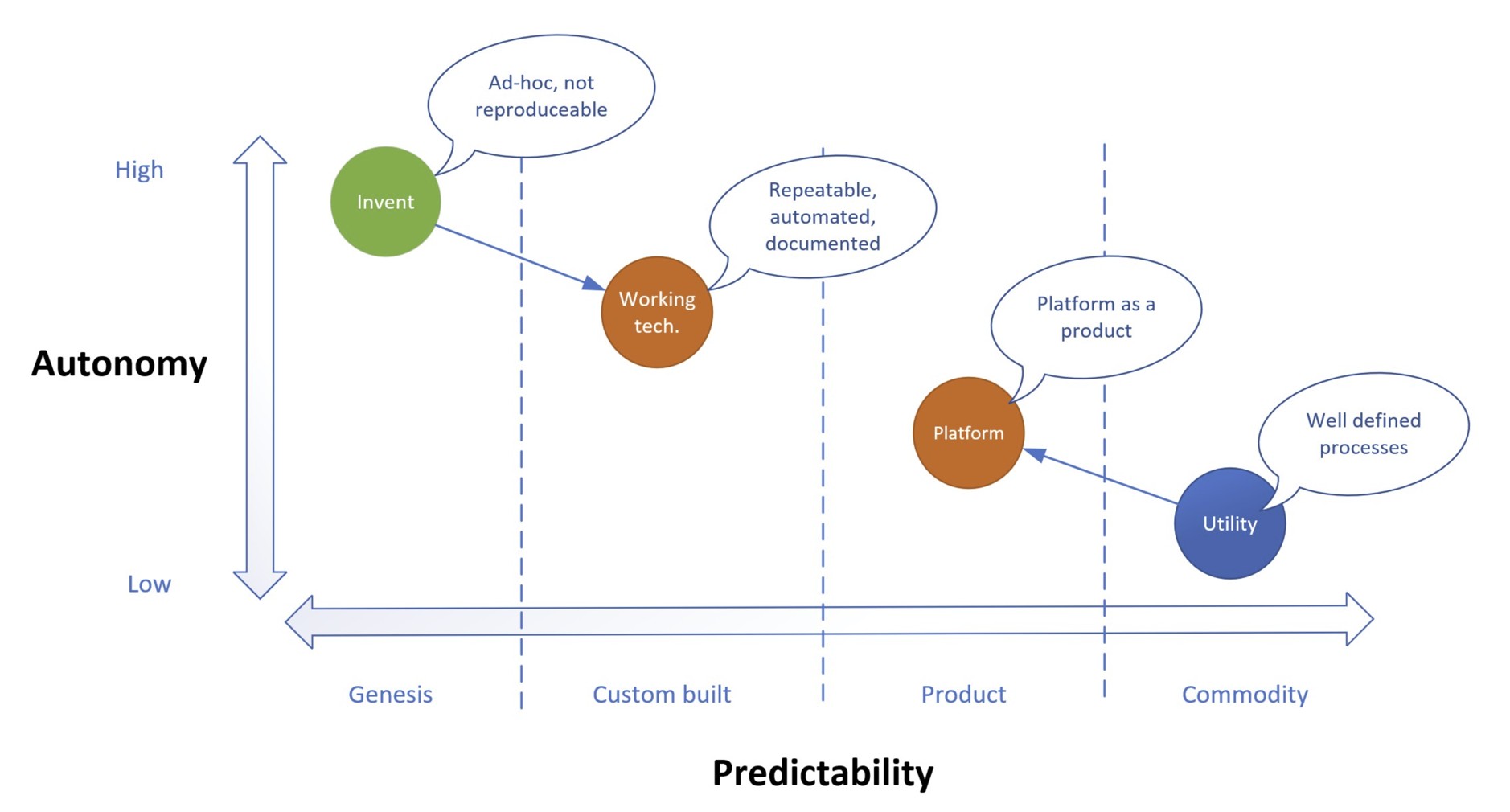
To make things worse top-notch developers disregard script languages and look down on the non-functional side of the house like a private DNS resolver or a cross-regional site recovery. My hunch: they do not care, let alone know much about these things and want it as a service. From time to time, I present on universities as guest lecturer. On one occasion I asked the participants (50+ BSc students in their graduation year) about the power consumption of an Intel server. No idea. How about a notebook: no clue. A hair dryer? One girl new it. Infrastructure is not sexy, not even when it becomes code.
Ways to handle this problem
There are multiple stakeholders in this game with multiple paths to follow.
Vendors - Reduce complexity
I picked Kubernetes as the veterinarian’s horse to illustrate the problem. People who dealt with Kubernetes and its automated deployment and configuration can attest that it is complex to implement and to run, even without its ingress headaches with private endpoints or a service mesh on top of it. For this reason, Microsoft has offerings like Azure Container Apps (ACA) or lightweight alternatives like Azure Container Instance (ACI) while allowing plain vanilla implementations on VM scale sets for masochists.
The downside is that this simplification comes with losing some of the configuration, security and monitoring capabilities. As a dreamer I wish we had a universal serverless compute resource on our hands like Azure Functions or Amazon Lambda. „Liberté, Égalité, Fraternité” for cloud computing: „Autoscaling, Resiliency and Security”.
Another approach is to hide the internal complexity altogether by moving to PaaS and in many cases to SaaS. This is exactly what Microsoft is doing eg. with items bundled into Fabric. The issue: the deeper you walk into the cloud forest (wandering to SaaS territory) the less likely you will ever come out. This reduction of complexity is not evil by definition, one could argue that it helps IT to create business value faster. But there is a catch: Once a senior executive of a large bank asked me what the biggest danger in cloud computing was. My answer was: if politicians on either side of the Atlantic go crazy. Two years ago, I meant it as a joke…
Service providers - Hide complexity
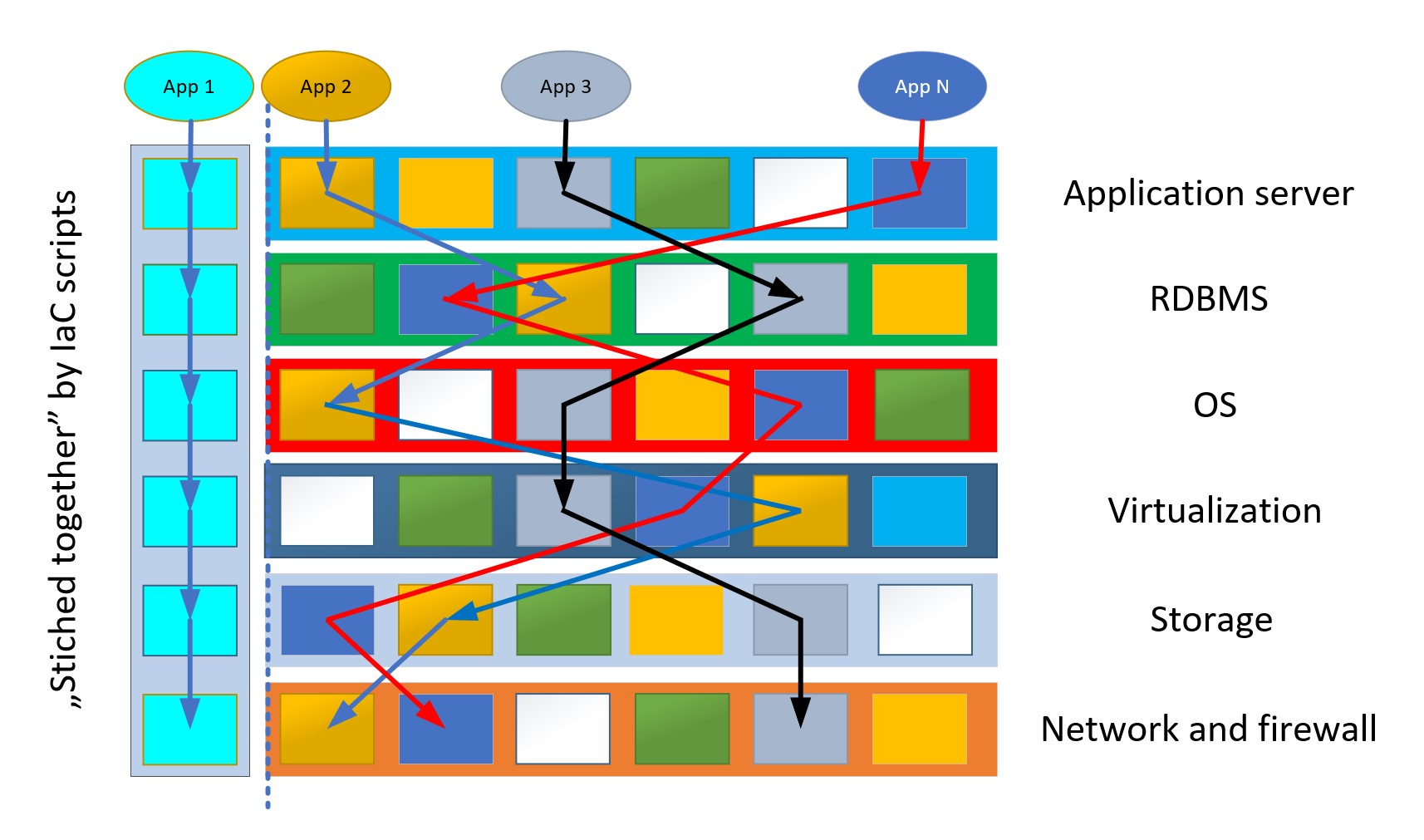
Complexity and skills shortage provide a business opportunity. In practice it means creating a layer between the offerings provided by the hyper scalers and their enterprise customers. This toolbox is a combo of blueprints for landing zones, IaC code base for cloud services, integration solutions for connecting the cloud instance with its on prem counterpart covering networking, identity management, service management and monitoring and automatically deployed policy sets to streamline compliance audits.
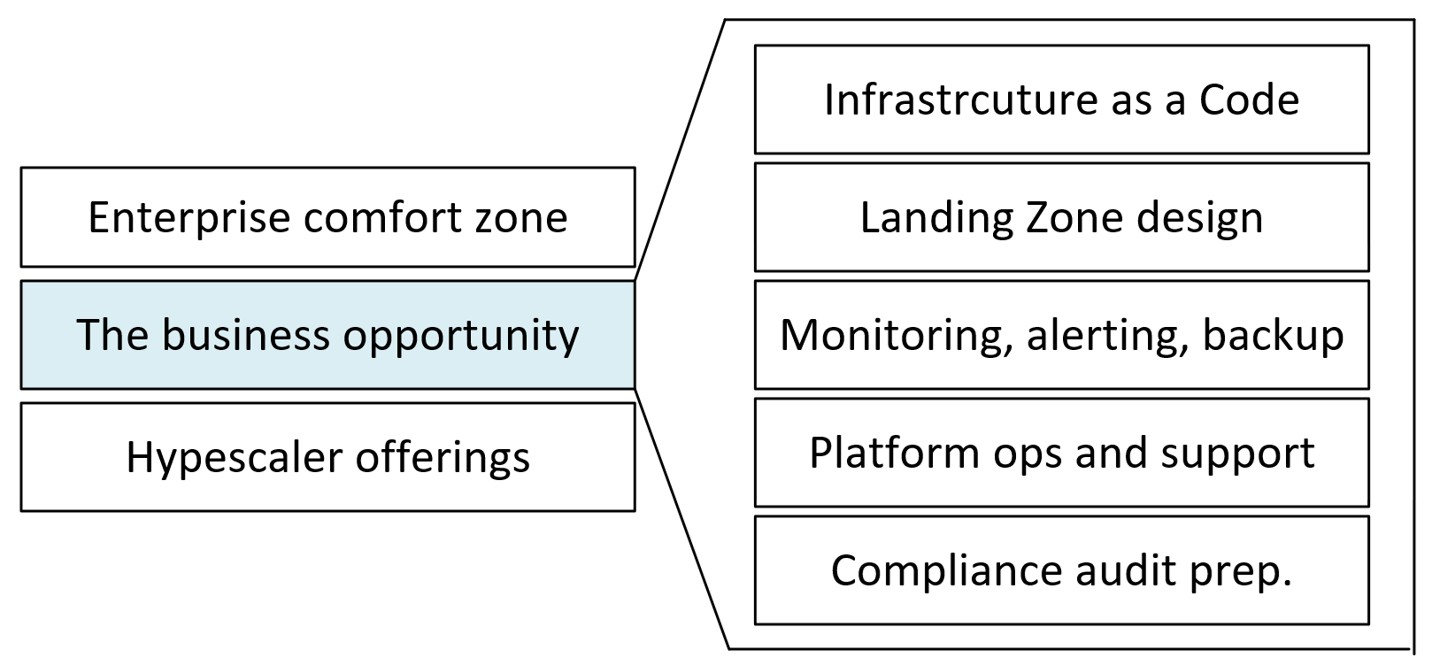
While it has its short-term financial advantages to start each implementation from scratch (if you are selling this service), only the thin upper layer of customers can afford it.
Warning: your Spice people are your golden goose, and not just for the profit you make on their billed hours. Ignoring the need for or screwing up with the foundations will lead to flawed implementations that will haunt you either as a security breach or a hard to run environment that your client will hate.
Engineers - Thrive on complexity
The revolution in infrastructure platform arena (Software Defined Storage-Network-Compute, Infrastructure as a Code) is the marriage of two – earlier distinct disciplines. This is reflected by the compensation data for cloud architects and DevSecOps engineers on Glassdoor: this is in the 130k to 230k USD gross annual range in the US. The rule of thumb is that whatever a top-notch IT skill costs in NY or London, you will get the same for one third of this price in Budapest, voila, flourishing Shared Service Centre business. So, we are talking about 50-60k USD annual gross for a good cloud devops engineer or a cloud security expert. The emphasis is on good. There is never-ending debate about the relevance of certificates. I recall a top-notch colleague at Microsoft from last century, when I nudged him about his certs (the lack of them) and offered that I would cover the cost of any MCP exam. He literally threw his MCSD certificate on my desk in two weeks. (he left the country 10+ years ago…) If you are good, the certs are doable and a good advertisement, but true, certs themselves are not enough. So Folks, learn and experiment! Cost is not an obstacle, a Coursera (ex. acloudguru) subscription is 30 USD a month, time is the problem.
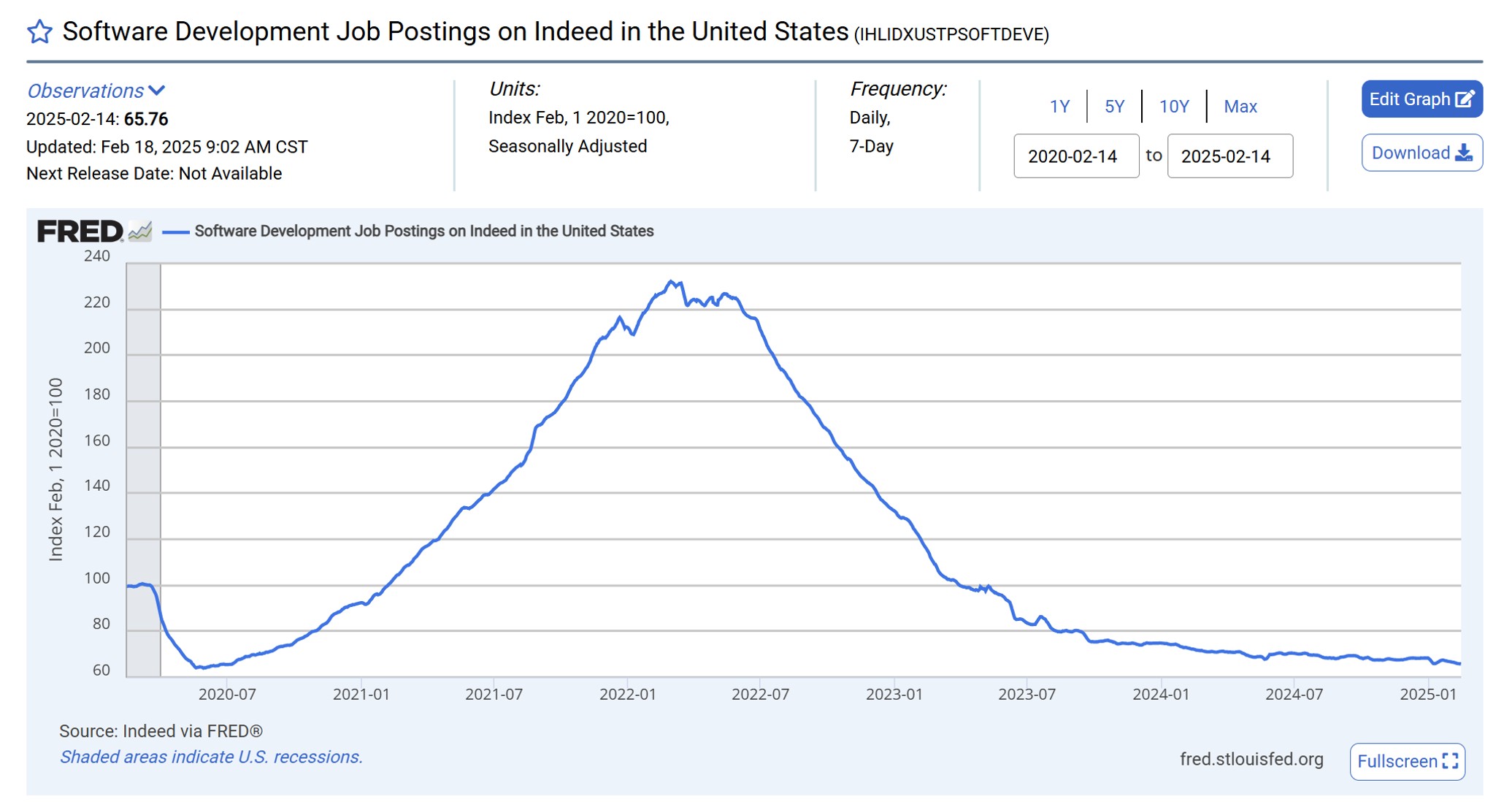
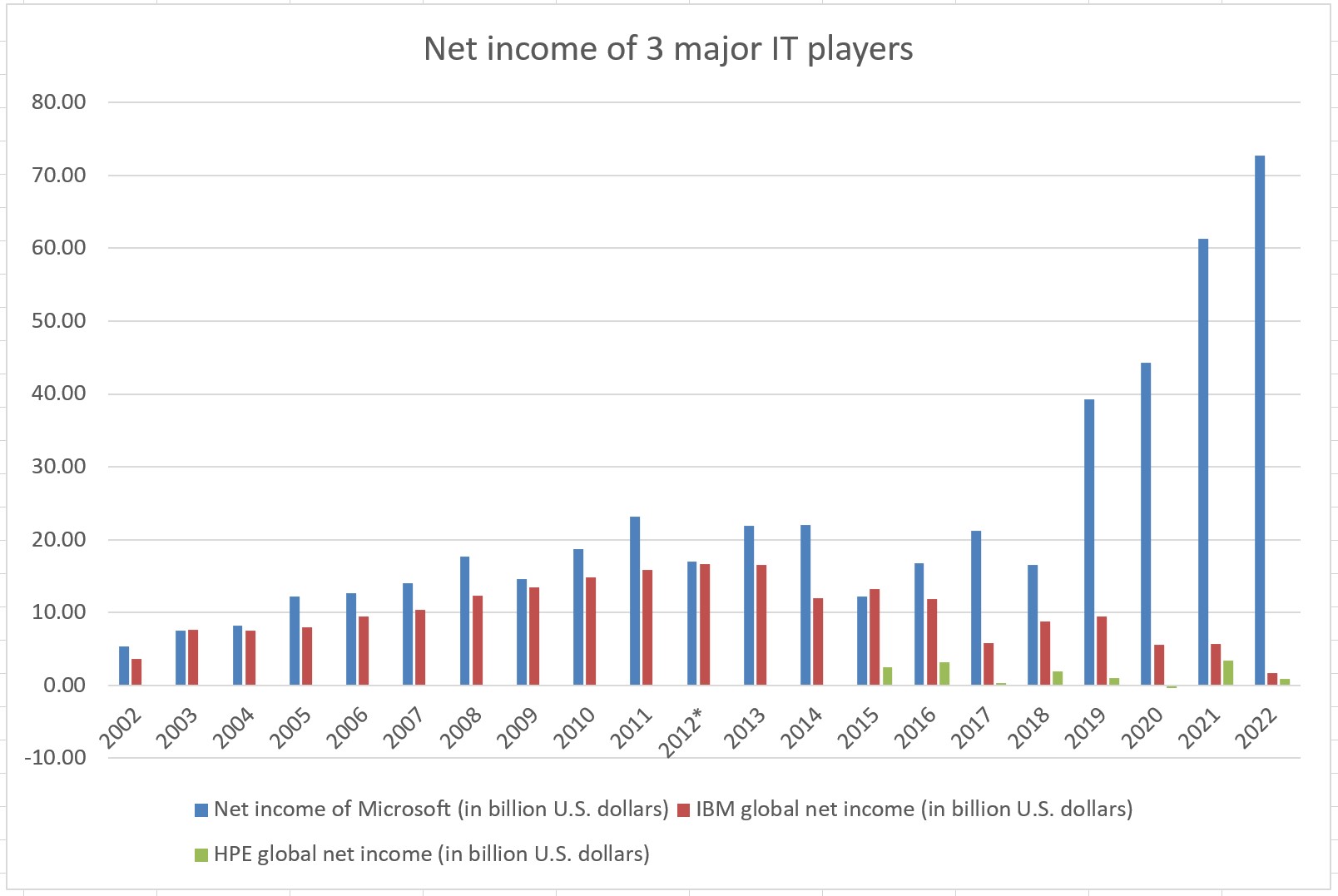
For the record: it is not all roses, as shown by the chart below. (I found similar data for Hungary.) The IT job market is not that pretty as it used to be, but it this fact reinforces my previous mantra: learn and experiment to stay ahead of your competition.
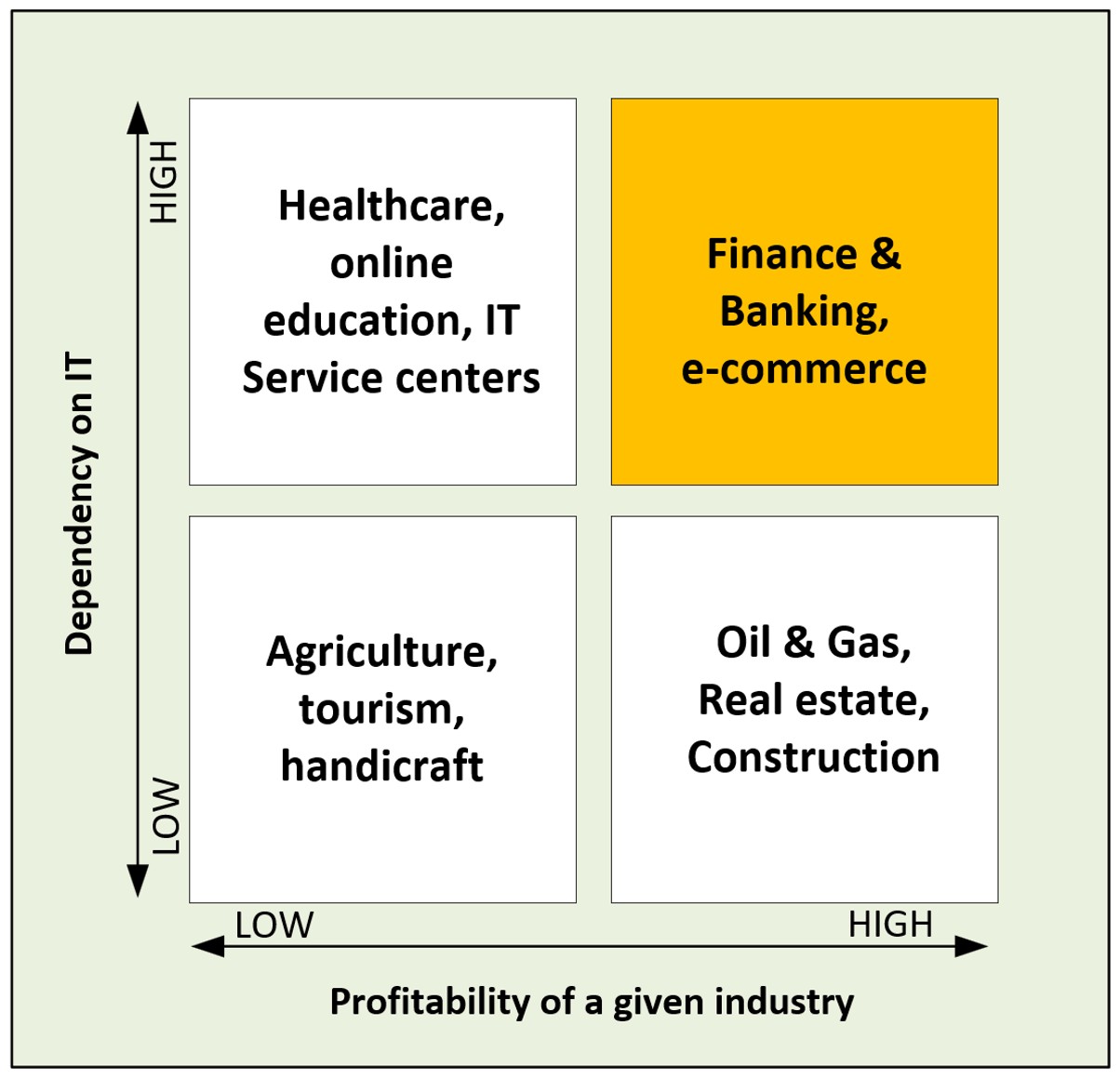
Another caveat is the industry and the location. Your compensation depends on the impact of your work on the outcome and the profitability of the sector you are operating in. The effect is a bit sad: healthcare and education could make a good use of top-notch IT if they could afford it.
Legend has it that when the famous bank robber John Dillinger was asked by a reporter why he always robbed banks, he replied matter-of-factly, “Because that's where the money is!” In the next chapter we will have a look at the second core problem with the cloud: hyper scale providers being greedy and siphoning out profit from the value chain.
As always, I appreciate your feedback.
Sources
- https://landscape.cncf.io/
- https://learn.microsoft.com/en-us/azure/architecture/guide/technology-choices/compute-decision-tree
- https://www.glassdoor.com/Salaries/cloud-architect-salary-SRCH_KO0,15.htm
- https://www.glassdoor.com/Salaries/devsecops-engineer-salary-SRCH_KO0,18.htm
- https://bluebird.hu/it-munkaeropiac/
- https://hu.jooble.org/salary/cloud-architect/Budapest#yearly
- https://fred.stlouisfed.org/series/IHLIDXUSTPSOFTDEVE
- https://www.whitecarrot.io/salary-progression/devsecops-engineer


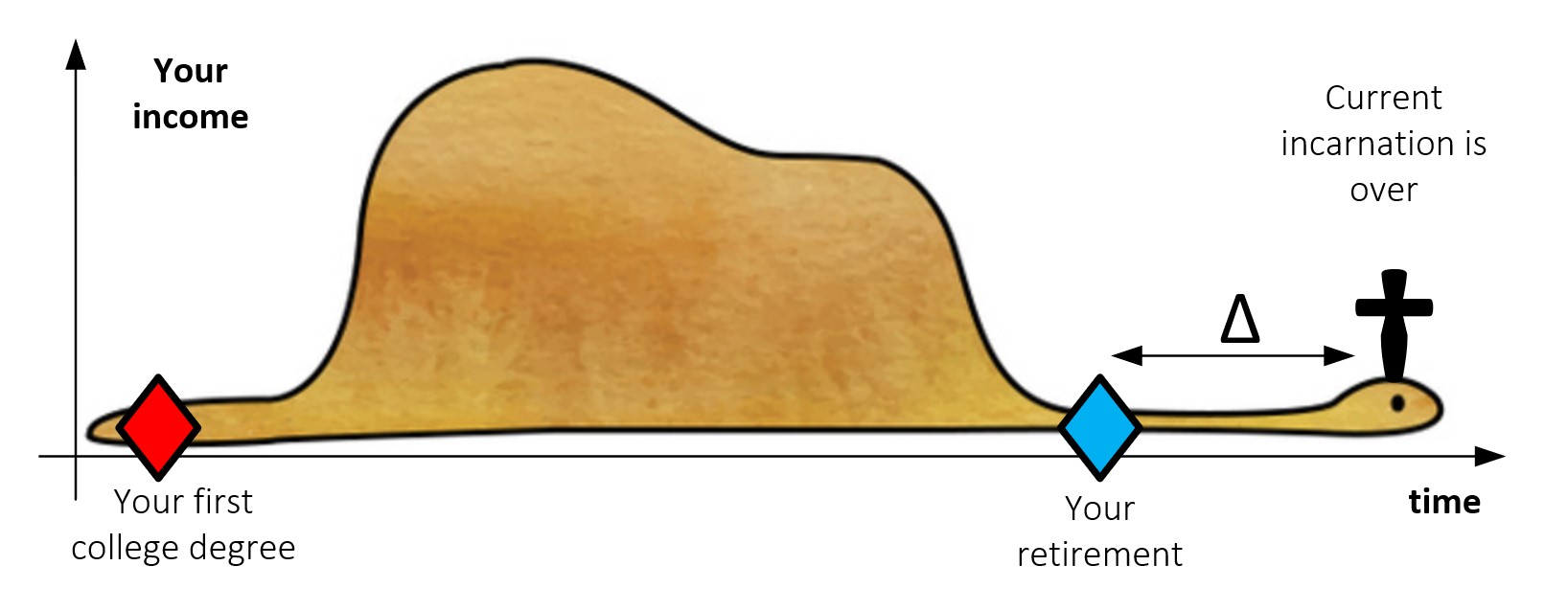
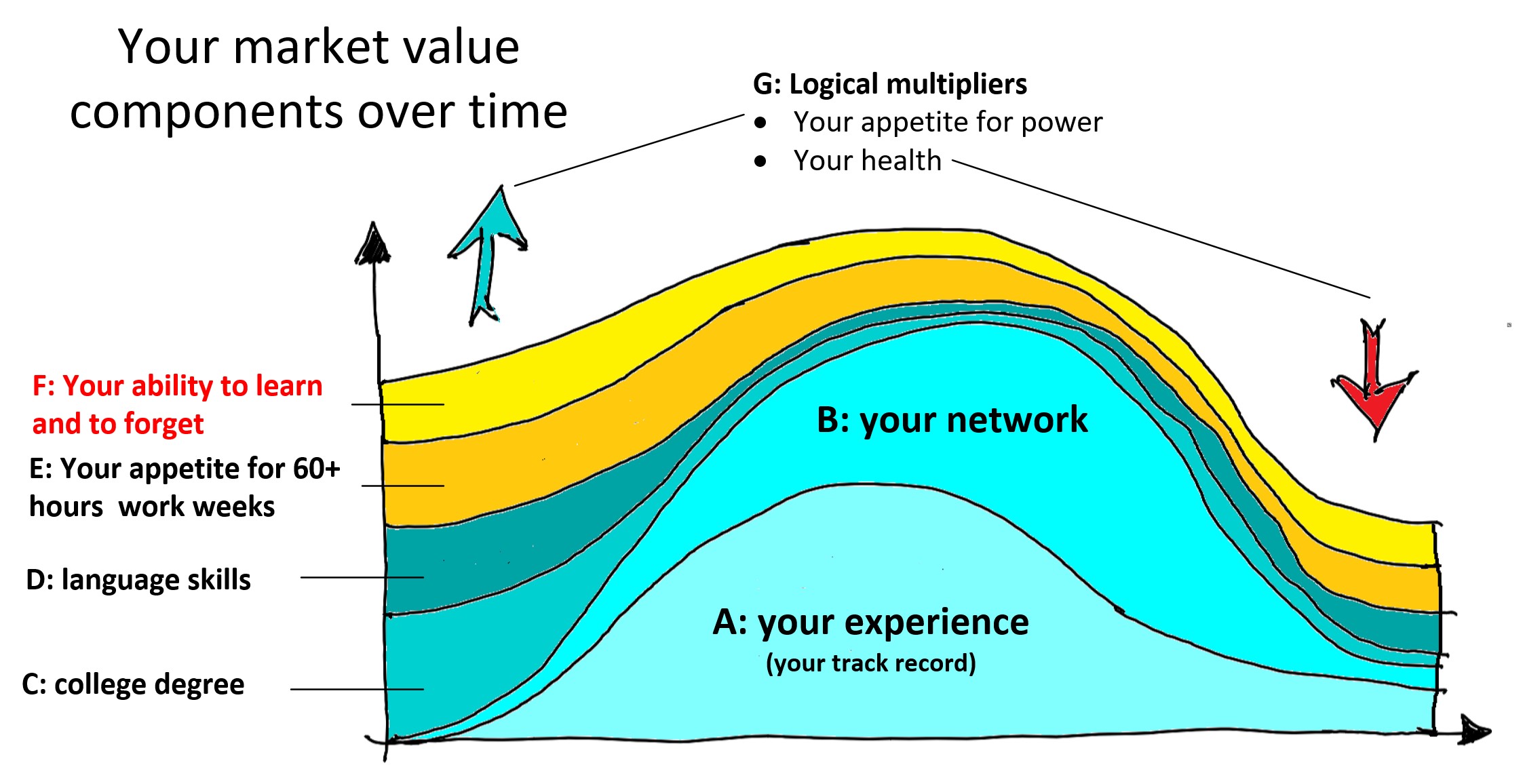

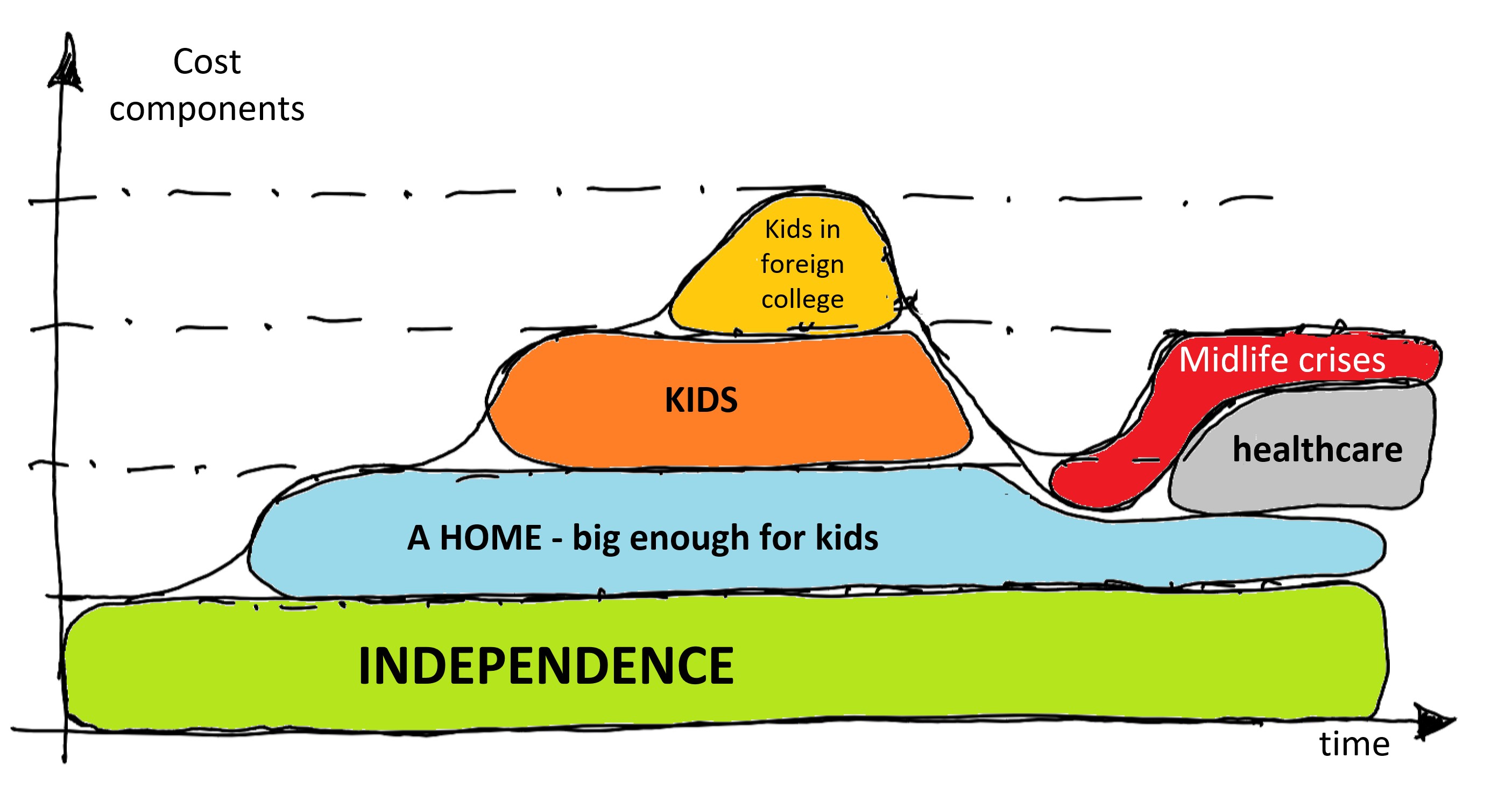
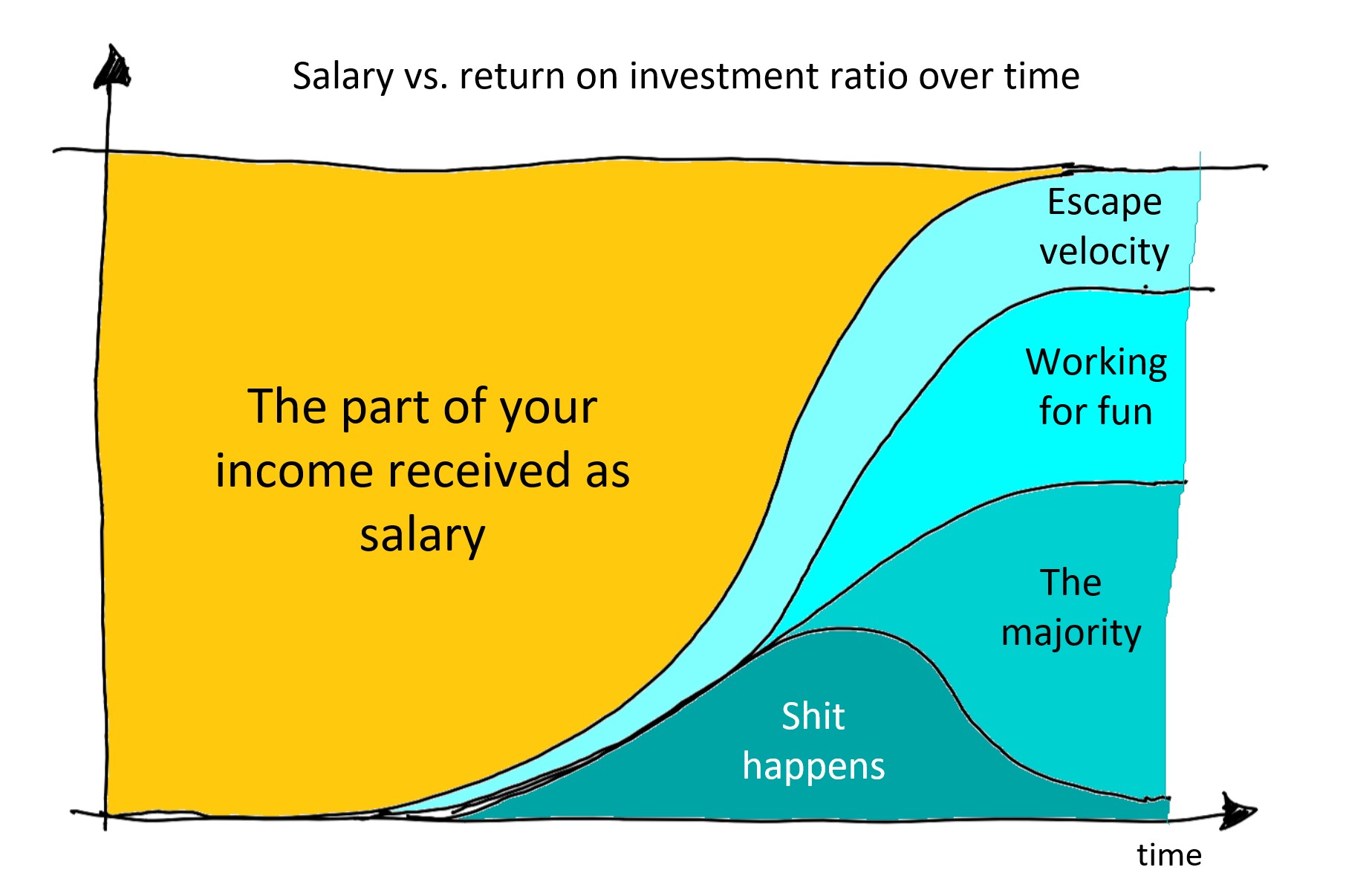 So here we are: the market is mostly right and becoming a follower of Siddhartha solves only a part of the problem. Here are the ingredients for preserving your livelihood over 55:
So here we are: the market is mostly right and becoming a follower of Siddhartha solves only a part of the problem. Here are the ingredients for preserving your livelihood over 55: