A couple of days ago I had the chance to talk with the CIO of a pharmaceutical company. He cited that the business does not track the time usage of the internal IT workforce, ie. acting as it was free and limitless. In another discussion with a banking executive, he mentioned that during a regular business review they marked 50 items as priority one. Earlier I had the chance to peer into the JIRA queue of a SW development team. There were 17 thousand (not a typo) active items in it.
Something strange is going on in the minds of these otherwise absolutely smart people that we need to set straight in order to go beyond the eternal blame on IT. In the following post I attempt to sort out a few basics. IT folks dealing with economists, you may want to read on.
If everything is a priority, then actually nothing is a priority
If you type in “meaning of priority” into Google, the first result is this: “the fact or condition of being regarded or treated as more important than others.” Webster will tell you this: “a preferential rating, especially: one that allocates rights to goods and services usually in limited supply”. In our case the service in limited supply is the capacity of your development team(s). This has an implication: Prioritization means ranking where only one item can be assigned as PRIORITY 1, all others will get a lower priority compared to this one. What made the aforementioned business executive tag 50 development requests as priority 1 was that all of these came from regulatory changes that he could not refuse to do. This increased demand - if not accompanied with an increase in the throughput of the dev team - will have consequences:
- Fulfilling a regulatory demand usually does not make you more competitive, it just keeps you in business, therefore when a significant portion of the dev capacity is burned on satisfying these, the business will get frustrated because of the functions they DID NOT get.
- It will make the dev team frustrated since their (internal) client is unhappy and will unleash their wrath on them for not meeting the business expectations.
- The dev team will learn to pick up the work load of those who escalated most efficiently (screamed most loudly or most recently into the right ears). A LIFO in operation, who yelled at you last will get served first. Warning: stress will increase performance only for a short period of time, after that will give way to apathy. (see János (Hans) Selye for the details)
- These priorities will change quite often, introducing one more factor, context switching. The bad news is that the human brain is wired in a way that handles context switching with a penalty. I would guesstimate that this phenomenon itself could reduce the team’s throughput by 2-3 %. (to use the juggling analogy, they will drop the ball sometimes…)
- One of the usual casualties of this conflict is technical debt. Neglected technical debt will increase the resistance of the system against any change, therefore the dev team will have to push harder. Another typical reaction is the reduction of training time. As a result, the actual throughput will decrease. (see the details in the Appendix.)
What you can do about it? Treat priorities as a ranking order, estimate the development effort properly (the most difficult part, requires regular checking with actuals) and draw the line at capacity. Do not try to force anything into the system beyond capacity, simply park them.
Putting more demand on the dev team than they can handle
Let us see what happens if you do overload your system. The short version can be described with the following diagram:
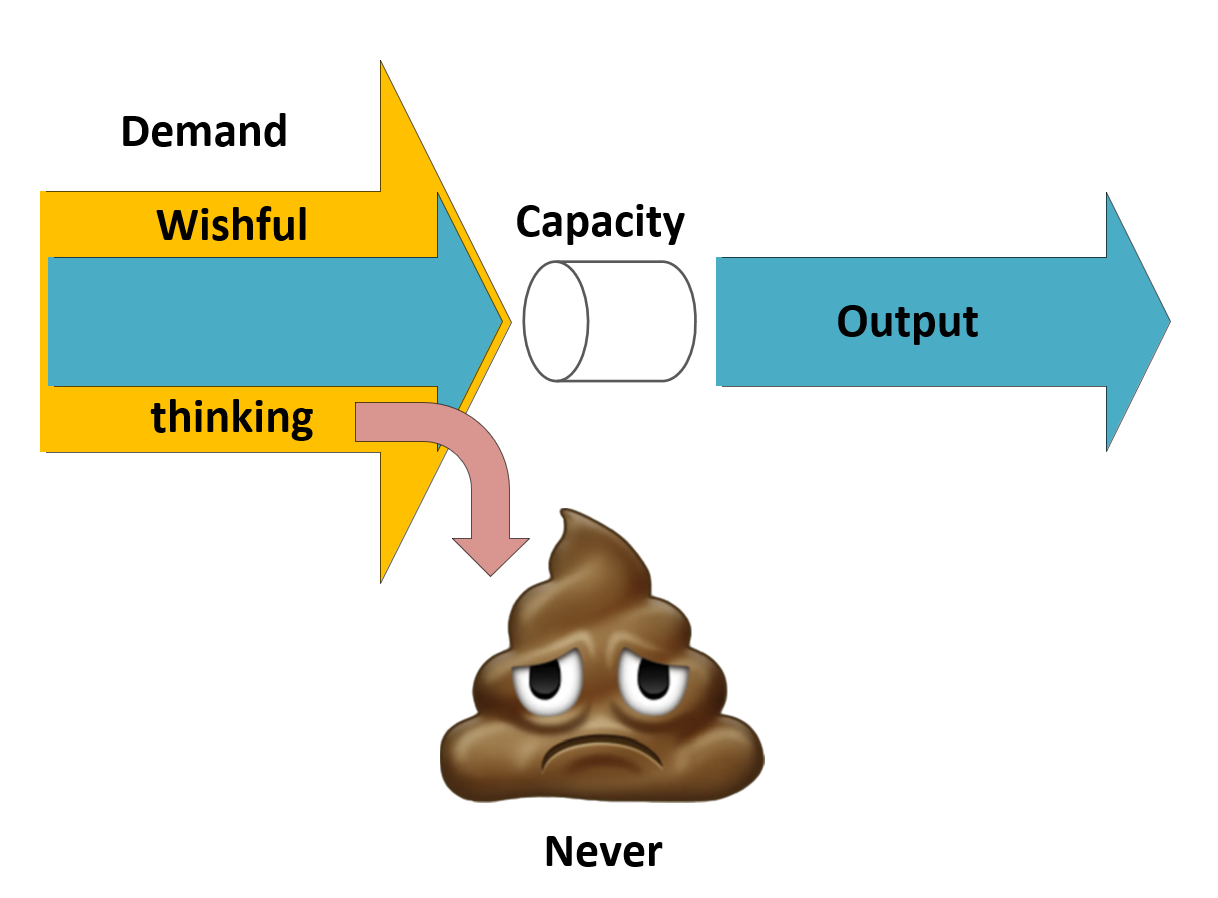
Borrowed from a presentation from Mary Poppendieck
Of course, the Business feels they were treated badly, a large portion of their asks were not fulfilled. They have two choices (after replacing the head of the team):
- reduce the demand by reducing complexity in the processes (and slashing the number of offerings) and then moving to COTS (Commercial Off-The-Shelf) solutions rather than demanding tailor-made solutions for everything. This move might have an impact on the competitiveness of the firm, so most business folks will not like it.
- Increase the capacity to serve the demand. (including tech. debt.)
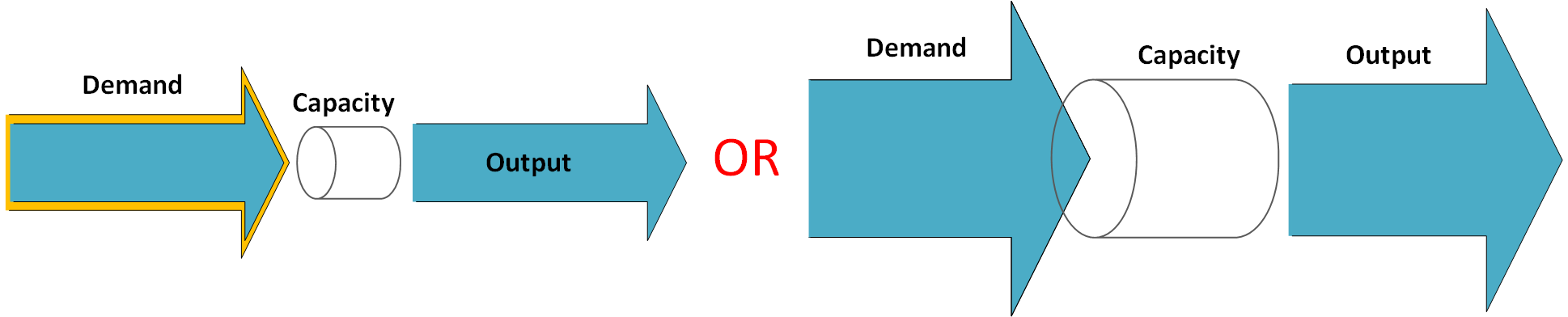
In the last part of this post, we will have a look at the ways to increase the capacity.
How to increase the capacity of your dev team without increasing the cost?
Imagine the software development team as an engine with a finite throughput (capacity). The Business cares about three things: this throughput, the quality and the associated cost. An obvious solution is to hire more developers, but this approach has its limits. Extensive growth worked in the USSR for a while (more raw materials + more labour = more output, yippee) but it soon reached its limits. We need to go beyond this and try something else.
Here is a 10 sec crash course on the Theory of Constraints: if you buy 10,000 respirator machines while you have only 4000 trained medical experts to operate them (1 operator for each machine, training one takes several years), what will be the upper limit of people who can benefit from these machines at a given time? Yep: Strengthening any link of a chain except the weakest is a waste of energy. (in our case money)
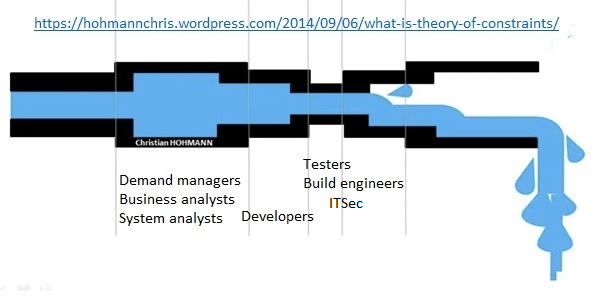
Imagine that this Software Development Engine is a pipe shown above. (Agile folks, this is a simplification, lower your guns.) You have to have the same throughput at each stage within this Engine, otherwise the one with the smallest throughput will determine the overall throughput. For this reason, it does not make sense to add one more Demand Manager to the team when the bottlenecks are the developers and the testers. You need to reallocate people to the weakest section of your value creation process in order to increase its overall throughput. A possible way to increase throughput is by using the Theory of Constraints (TOC). The TOC improvement process is named the Five Focusing Steps:
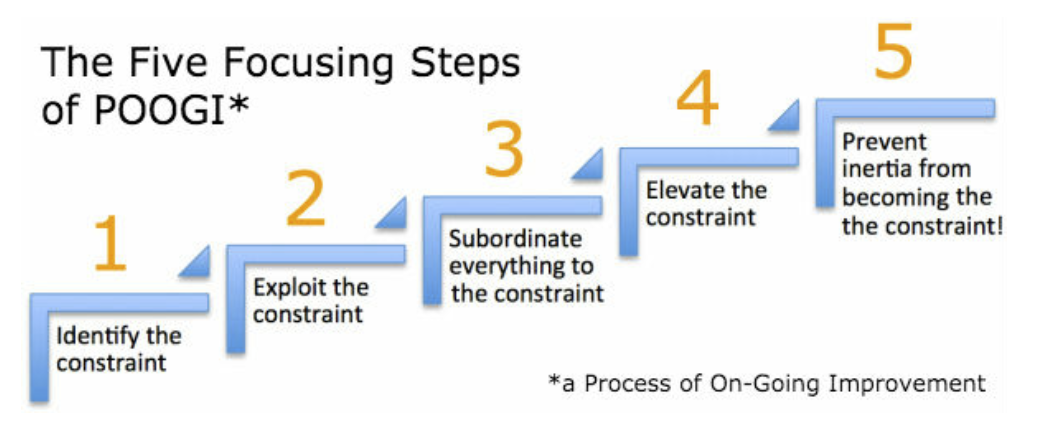
https://www.tocinstitute.org/five-focusing-steps.html
There are various methods to find these bottlenecks in a software development process. One of them is value stream mapping. Once eliminated the bottleneck be prepared to find another one somewhere else in the process. This is a whack-a-mole, but one with great efficiency gains.
If want to read on, there is a great article on this topic: Theory of Constraints Best Practices by McKinsey Alum (stratechi.com). If you want to dig deeper, there two amazing books I recommend:
- The Goal: A Process of Ongoing Improvement (the original book by Goldratt)
- The Phoenix Project (A Novel About IT, DevOps, and Helping Your Business Win) – a must read for any business leader who wants to get closer to IT.
Henry Ford knew it – we just need to copy him
While we are not at the point when can automate the creation of code, we are certainly at (beyond) the point when we can automate the testing of the code designed and written by humans. In theory one can automate most key steps in the SDLC process, including the automated creation and initialization of the test environment, the build process and the testing itself. This idea has one caveat: those who can create this magic are developers (okay, test automation folks with strong scripting skills) themselves. Test automation became a separate discipline that one needs to learn.
The takeaway: if you are not happy with the throughput of your development engine, do a thorough analysis on the whole value creation process (eg. with value stream mapping) and eliminate the constraints by repurposing existing capacity from another part of the engine AND automate any repetitive tasks, especially testing (+ creating the test environment) and the build process.
As always, I will be happy to get your feedback on this post.
PS: For those with a bit more appetite for analytics, I put together a model to explain what happens over a longer period of time. Let’s assume that the throughput of your dev team over a period is 100.
You have 3 types of user stories: Small ones that cost 1 unit of effort, Medium ones that cost 3 units, and Large ones that cost 5 units. (a simplification from the original 5 T-shirt sizes) A certain request will either fit or will not fit into a given period. (again a simplification, not allowing for partial jobs.)

There are 3 priorities, from Prio 1 to Prio 3. It is important to note that we do not put into consideration the actual value gained from a user story, we assume that the value gained is a linear function of the corresponding cost. (If you cannot measure and cross charge the cost of any product or service then your ROI calculations can only justify a decision that you already made, right?)

In the first period (year) you will cover 91% of the known requirements. The business does not know about technical debt OR wants to allocate too much time to sharpen the axe (aka. training). Technical debt is like financial debt, you take a loan today and will have to pay it back with interests later. This interest is the system’s increased resistance to change. This comes as a penalty on the total throughput of the dev team, so this is down to 97 units vs. the 100 you had last year.

In the second year we assume that the new demand is the same as last year, BUT we have to take care of the load that spilled over from last year. Your performance in the eyes of the business is down to 81% and you still did not touch the tech debt that will haunt you soon.

At the end of year 3 your performance is down at 71%, with an ever-increasing pile of tech dept waiting for you. This model also explains how those gigantic amounts of open JIRA tickets are generated.