
Summary: Cloud computing is expensive. The recognition of this fact will lead to a small-scale return to on premises computing while importing the cloud operating model. More importantly it will trigger a change how IT and its internal customers think about and use computing resources. This is a commodity, but with a price tag.
A few months ago, the business plan published for the Lyft IPO shed some light on the scale of computing cost a cloud only IT has to live with. (a 300 million USD payment obligation to Amazon for the next 3 years) Cloud computing is not cheap, that is the sales pitch only.
For the record, cloud providers are not greedier than their commercial clients, the problem is NOT with the pricing. AWS runs with 30% gross margin while it uses all levers economy of scale can offer like 20+% discount on parts (eg. from Intel) and 30% or more on electricity, not mentioning the efficiency gains in operating cost and on the plant itself. Bottom line: you are unlikely to be cheaper in a 1-kilogram AWS CPU vs. 1- kilogram on prem. CPU shootout.
There are two forces at play here:
- Compute and storage workloads moved to a metered environment while the consumption patterns stayed unchanged from the honky-dory “it’s a flat fee we already paid” times. Cloud providers simply exposed the uncomfortable truth about enterprise consumption habits. (it is like my kids listening to the music of Youtube videos on a 4G metered internet connection.)
- The other factor is the “Kids in the candy shop” syndrome: If you give IT guys instant access to a virtually unlimited computing and storage capacity without a strong cost control, a surge in consumption is inevitable.
Why enterprise folks leave the lights on in their traditional on prem. DC environments? I think there is a combination of technical, accounting and emotional factors at play.
- The technical driver is straightforward: it would be difficult to keep in mind what component is dependent on which another component, let alone the existing application layer is unable to start an external resource it needs, since it was written with the assumption in mind that those resources are just there. If they are not there in that very moment when they are needed, the app throws an alert and stops. There are nasty traps ahead for those who do shut down their servers. I remember a company who shut down their AS400-s for maintenance after several years of no downtime. Half of their disks did not spin up after the bearings cooled down between Christmas and New Year’s Eve. Simply put shutting down a DC is a project by itself.
- The accounting aspect is less obvious, but equally powerful: Most enterprise IT acts as a cost center and the finance folks demand that they distribute every dollar IT spend to their internal customers. This allows no tangible unassigned compute/storage capacity within the IT department, therefore when a new demand arrives, they cannot serve it right away. They need to procure it. This is when procurement (the “Vogons”) arrive.
- The “my precious” syndrome: back in my childhood when a baby was born in Eastern Germany, the parents shelled out the initial payment for a Trabant (for those who missed it: an automotive gem with a two stroke engine with 22 HP, a fiber reinforced paper body and a minus 2 stars NCAP evaluation) to make sure by the time the kid turned 18, the car would be there. You can imagine how valuable a second hand Trabi was… The same thing is at play in the modern enterprise: the lead time (approval, procurement, “unforeseen” dependencies with the telco guys) between requesting a new server to actually deploying a workload on that box takes 5+ months. This is not a surprise that the business unit – once it got its precious new HW acts like Gollam, it would not give it up (or just shut it down) even if the given server was idle for months. This behavior is the key driver behind the server utilization figures in range with a steam engine.
What can we do about this problem? As always there are two approaches: fight of flight.
FIGHT:
- The low hanging fruit is monitoring and reporting any cost to the business unit which is behind that cost. Link the cost to the payload and pair it with the utilization: “this cluster runs a credit app that you retired last year so it did nothing in the last 4 months but cost you 17k USD.” The thing works best when you break down cost to the employee where you can. (eg. dev machines) I guess cloud cost optimization will become a separate business on its own right soon.
- In case of databases show the number of transactions on that DB in the last few billing periods. Introduce storage tiering in sync with the data lifecycle along the capacity-IOPS-cost dimensions and come up with saving suggestions like moving the workload to a cheaper availability zone, or to reserved instances, or where the workload permits moving to spot instances.
- Autoscaling, while seems like the best option, is a double-edged sword: Enterprises care more about the predictability of their cost than a potential reduction to it. This is okay to spend a lot as long as you are within budget. Not mentioning planning practices based on last year’s actuals: “if you underspend your budget, we will shrink it for you.”
- Needless to say, the whole thing will work only if there is a strong incentive on the business to care about these reports. Otherwise they just archive it.
- The tough part is changing the mindset of both the IT and their internal customers: you need to make them realize that “their precious” is actually a disposable resource, a commodity but with a price tag. In order to get there, you need to make sure that provisioning and tearing down compute capacity is absolutely painless and fast. For the record: any compute-storage-networking environment is disposable only when the payload has no direct references to a given resource. Static IP addresses hard-wired into the interface code anyone?
- Make the internal IT cost breakdown as similar to the cloud providers’ bill as possible. Let talented folks work on the cross-charge mechanisms and make sure they read the works of behavioral economists first.
- A word on vendor lock in: I have lingering doubt about cloud brokers due to the added complexity, but I am sure most large enterprises will end up with 2 if not 3 public cloud providers in the long run. The vendor lock-in will be created not by the cloud providers directly, but the payload, ISVs writing their apps hooked into specific cloud offerings. (eg. “my stuff works only with S3”. De ja vu Windows in the 90’s…)
FLIGHT:
- In case of predictable, static workloads it might make sense to bring it back to on prem. (one might ask why you moved it to the cloud in the first place, but it surely happened during the reign of the previous CIO.)
- If you do bring back data and workloads from a public cloud to your own DC make sure you do not fall back to the old habits, ie. you implement the cloud operating model instead of the ancient regime. Automated provisioning and auto-scaling, config and build artifacts in JIRA just like code and all other goodies the big guys invented. And yes, convince the CFO that you are an internal cloud provider who has to have spare capacity.
Let me finish this blog post with my favorite song from the Doors: “When the music’s over, turn out the light!” As always, I appreciate any feedback and comments.
----------------------------------- addition based on feedback ----------------------------------------------------------------
I received a fair amount of feedback that prompted me to follow up on it. So here is the add on to the original:
So here is my theory: the compute platform development in the last 15-20 years can be viewed as an improvement in area approximation, aka. an areal integral, where the f(x) is the computing workload and ∆x is the time required to bring up-down a new compute instance. I am talking about this:
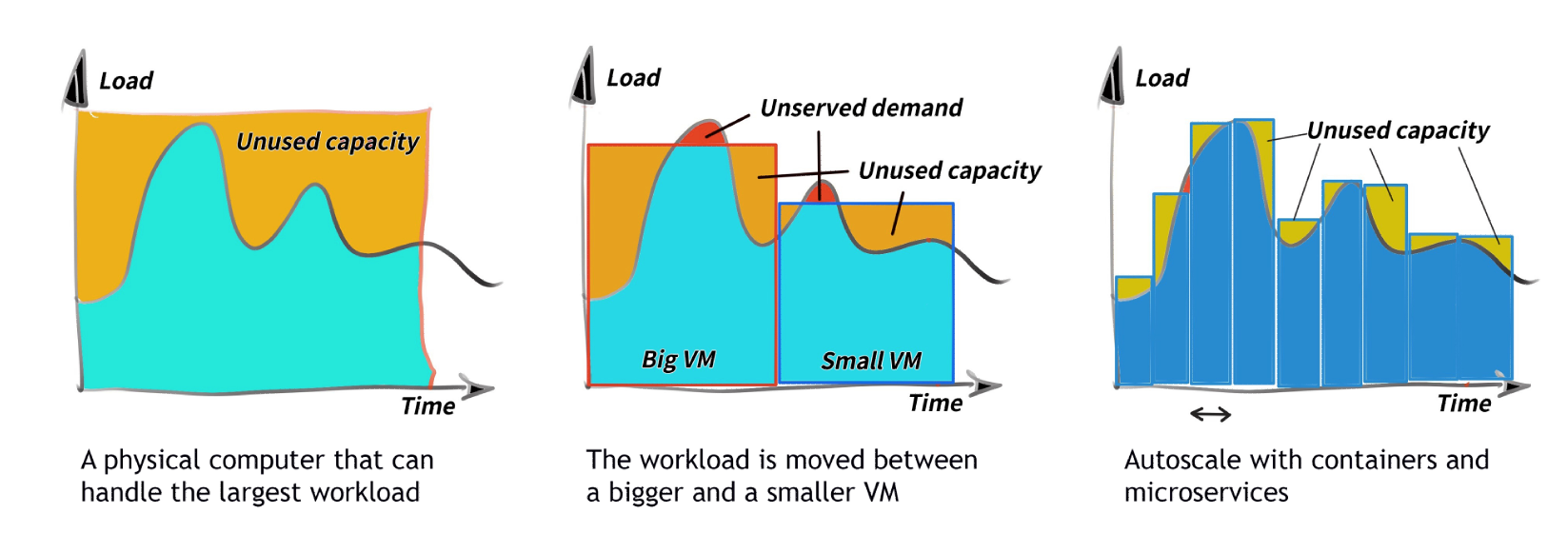
- Back in the mainframe days you bought the compute capacity that your valet could afford and prayed that that iron could handle whatever the business threw at it. These computers ran the core banking or billing app ie. the backbone of your business, having a few hundred interfaces implemented in the traditional spaghetti fashion. Replacing a mainframe during its lease was expensive, therefore ∆x was measured in years (see the graph on the left). Even if you had another mainframe (eg. for DR purposes), splitting the peak workload between the two was difficult. Applications on these beasts were designed with scale up in mind, aka. “buy a bigger machine if you need more juice”.
- Fast forward many years: your core app was running on a VM, therefore in theory you could move the workload from a small VM to a large VM in a few hours (still talking about scale-up) to respond to an increase in demand. ∆x was measured in hours (see the graph in the middle)
- In the future – running your application payload on containers you can add or remove compute capacity very fast IF you completely rewrote your app from the old scale-up behavior to scale-out. ∆x will be measured in seconds (see the graph on the right).
My forecast about the pendulum swinging back a bit is valid for IaaS workloads only that were migrated to a public cloud provider as is and where the user and IT behavior did not adjust to the metered environment then the CFO dinged the CIO for the increasing cloud spend. As Gabor Varga put it: "Think about Cloud as a continuum rather than a binary classification of deployment models. That mental frame would help everyone understand that IaaS has more in common with onprem than with true PaaS or SaaS which are higher abstraction levels of IT resources." Yes, this is why one can walk backward sometimes. The new billing schemes introduced by serverless offerings (like this: https://cloud.google.com/functions/pricing) might stir the pot and surely will demand even more scrutiny of the cost evaluation. (thanks for Zoltan Szalontay for bringing it up and for Sandor Murakozi for helping me we real life examples.)
Sources used for this article:
- https://www.rightscale.com/blog/cloud-cost-analysis
- https://assets.rightscale.com/uploads/pdfs/RightScale-2017-State-of-the-Cloud-Report.pdf?elqTrackId=4dcca4a2a62b42f49bccd34f3ec7fbdd&elqaid=4407&elqat=2
- https://searchcloudcomputing.techtarget.com/definition/cloud-sprawl
- https://www.dellemc.com/en-us/collaterals/unauth/analyst-reports/products/converged-infrastructure/vxrail-aws-tco-report.pdf
- https://www.stayclassyinternet.com/articles/investigating-AWS-pricing-over-time/
- https://perspectives.mvdirona.com/2010/09/overall-data-center-costs/
- https://www.quora.com/How-much-will-it-cost-to-own-a-small-scale-datacenter
- https://www.datacenterdynamics.com/news/research-larger-data-centers-make-considerable-savings-on-operating-costs/
- https://ongoingoperations.com/data-center-pricing-credit-unions/
- https://www.brightworkresearch.com/saaseconomy/2019/01/03/the-rise-of-commodity-servers-in-the-cloud/
- https://www.facebook.com/PrinevilleDataCenter/videos/10150385588936731/
- https://deepmind.com/blog/deepmind-ai-reduces-google-data-centre-cooling-bill-40/
- https://www.stayclassyinternet.com/articles/investigating-AWS-pricing-over-time/
- https://www.businessinsider.com/lyft-ipo-amazon-web-services-2019-3




