

Sponsors have the tendency to want to know how any project in their realm is getting along and above all what they get for the money that they threw at us. They ask the same question over and over again: Are we there yet? To be honest, when you requested a few million bucks for a cloud implementation, it makes sense to know what “there” is and to be able to tell when you reach this point. This is #2 in the cloud related articles dubbed the Horseshoe bend, focusing on the measurement of the outcomes of a cloud implementation.
In case of a cloud adoption program there are four sets of folks in your organization whose interests you need to cater for. These people are the business (the guys who fund the whole thing), ITSec – the knights who say Ni (or rather No), IT Ops who see this whole thing as unnecessary and last but not least the compliance folks representing regulatory scrutiny. The rest of this article attempts to set reasonable targets for each stakeholder group, define metrics for each of these targets and at the end to prove why you should not stress the whole thing beyond reason.
The business metrics
- The ability to respond quickly to a surge in demand (or a sharp decline for that matter) – this is a no-brainer, as long as you apply the ground rules of Infrastructure as a Code. (AND as long as your cloud provider does not run out of steam.) (Metric: being able to spin up additional compute/storage resources within a few hours from the demand.) WARNING: it only makes sense to dynamically scale the infrastructure if the application layer is able to take advantage of this capability.
- The speed of infrastructure design and implementation from the request until it actually goes live. This is the one that has a great effect on developer productivity. The way to do it is by using technology building blocks and the underpinning blueprints combined with automation. I mean full automation, with no manual intervention at all. This will require that ITSec and ITOps GIVE UP pre-control and to move to post-control with near real time policy violation detection. Approve the design, not the actual instance and check if we strayed away from this design.
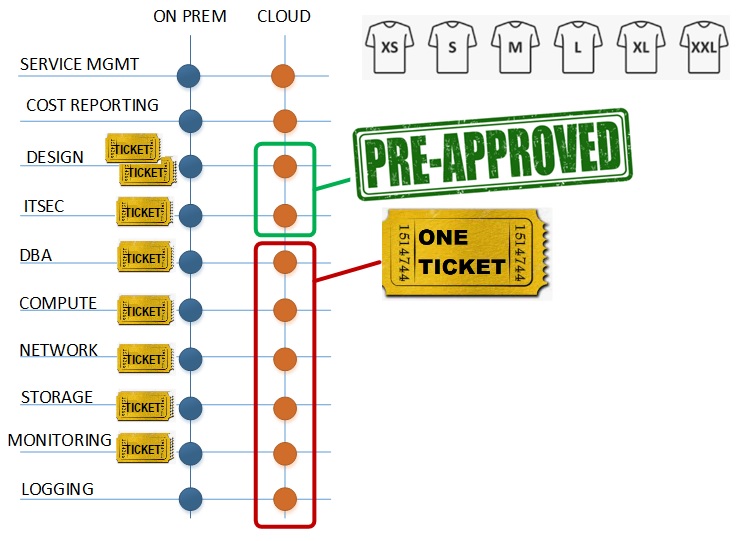
The caveat is when you need to link your shiny new cloud environment with its on prem buddy carrying a bunch of legacy technologies and more importantly legacy processes. It is like Lightning McQueen pulling Bessie. Yep, it may not be that fast… (Metric: the time between the first and the last related ticket designing and implementing an IT infrastructure should be 25+% faster than its on prem counterpart.)

- Cost transparency – this is easy, just implement proper tagging and a data analysis/visualization tool (a pedestrian Excel with a SQL backend will do) on top of the analytics report. Warning: it can be a double-edged sword in environments with poor cost transparency since – while it indeed can tell to the penny who spends how much on what – this can be pitched as a weakness compared to an on prem alternative where the costs are unknown or where the actual user of a service does not feel the pain of their extravagant requests. (Metric: report AND forecast the cloud spending by cost center. Produce cost reduction suggestions as a bonus.)
- Technology adoption speed – The marketplace of any major cloud provider contains thousands of applications, development/management/monitoring tools, two magnitudes more choices than your on prem IT can handle. Balance is the key word here, too much freedom would throw the monkey wrench into IT Operations, while banning the inflow of new technologies would defeat the purpose of the whole thing. Clogging the path of innovation is a very bad idea, therefore when ITOps no longer can handle a new technology, apply the “you build it, you run it” principle.
The Technology metrics
As long as you opt for IaaS, you will have to deal with the same duties as if these VM-s were in your data center. And in some cases, you cannot avoid deploying VMs in your cloud subscription. Unless you plan to operate what you have built you need to realize that demanding the same processes as used on prem is a legitimate ask from Ops. The problem arises if those processes are siloed and littered with manual steps. IMPORTANT: The strength of a cloud infrastructure is given by the level of integration between the components. As soon as you start to operate the various components in separate silos, you are going to kill the essence of the whole thing. This begs for a dedicated Cloud Operations, but it would question the status quo.. Anyway, here are the technology metrics:
- Know what you have: as long as you deal with a computing resource deployed for longer than a few hours you want it to be in your CMDB. This is obvious but easily forgotten that this CMDB is on prem. (Metric: all CI-s are known by the CMDB)
- Config management: Automation can be a key differentiator here. Rather than trying to find an error in a configuration by eyeballing config files one could write a code that makes sure that reality equals the design. (Metric: the number of differences between the designed and the actual parameters.)
- Monitoring: Cloud providers use the same components, architectures, hypervisors etc. (but not the same processes) that you do, therefore are susceptible to the same errors like their on prem counterparts. Things will go wrong sometimes, so you have to implement monitoring. For a smooth coexistence feed the metrics streams into the traditional on prem monitoring tool and its cloud native alternative as well. (Metric: key metrics are fed to a monitoring system with alert thresholds defined.) WARNING: no matter how good your infra DR capabilities are if the application layer is not prepared to use these capabilities.
- Incident management: The real thing is how fast and meaningful your reaction to an alert is. This topic is dealt with in ITIL, so I rest this case with the assumption that this is mostly the same as on prem with one key difference: DO NOT to allow anybody to temper with the production environment manually since it will create a collision between the parameters set by the automation script and those set by an Operations person. The question is if you will have the discipline to make changes to the IAC code, then run this code or you cannot resist the temptation to make manual changes. My hunch is that you will violate this rule sometimes…
The ITSec metrics
None of us want to fall victim to a hacker attack. I learned the following maxim from ITSec people who were clearly beyond me: “You can inflict way more damage with 1 million USD than you can avoid with it.” The playing field is not even. This is that should make you ITSec cautious. The problem is when you achieve relative strong security posture at the expense of the business flexibility. The following list is just scratching the surface.
- Using Multi Factor Authentication (MFA) for any activity – in case of public cloud you are exposed by definition, your first line of defense is the identity of the users. You need decent Identity and Access Management (IAM) tools and processes. The very minimum is to use MFA in all cases, not just for the admins. (Metric: yep, MFA for all.)
- The granularity of admin rights aka. reducing the attack surface: I recall my early days in IT in 1990 when I felt Mr. Important when I got the admin access of the Netware 2.15 server at my first workplace. Of course, it was permanent, revoking would have meant a demotion, right? Wrong: You do not need admin access to anything unless you have a job to do with that system. Using Privileged Identity Management (PIM) is an essential way to reduce the attack surface, namely time. Of course, its efficient use is based upon the assumption that the PIM approval process is fast. In fact, the best thing is if you do not use admin accounts to do anything in a production environment, but use service principals instead. (Metric: admin rights are granted for a few hours to the least number of people when needed. Dig the global admin account in a safe place and use it only as a last resort.)
- Cloud native security metrics and best practices: cloud providers will create assessments of your cloud implementation, suggesting improvements. 3rd parties will also produce reports on the known vulnerabilities (eg. Sysdig, F5, Read Hat) Read these and act upon their findings. It is wise to procure a penetration test against your own implementation on a regular basis. (Metric: a predefined security score – likely from your provider and the speed of reacting to these findings.)
The compliance metrics:
d'Artagnan did not worry about the duel waiting for him at 2PM with Aramis since he knew he probably would be dead by this time due to his duel with Porthos scheduled at 1PM. I am more worried about hackers than auditors, so I do not have metrics for this area yet. (okay: being in compliance with a the regulatory guidelines whatever their real meaning is.)
Summary – how to prove to your sponsor that you reached the goal?
The next paragraphs might look weird after pages spent on defining them: these metrics are less relevant compared to what they miss to capture since they cannot measure it: the impact of the knock-on effects of a good cloud implementation. As Roy Amara put it: “We tend to overestimate the effect of a technology in the short run and underestimate the effect in the long run.” I am convinced that cloud computing is going to have a profound effect on how we do computing in the future. It is not an end into itself but an enabler, and we surely do not comprehend all of its implications since it’s hard to notice things in a system that we are part of and it’s hard to notice the incremental change because it lacks stark contrast YET. As always, I will be happy to learn your feedback.



