In regulated industries you are required to produce an exit plan before you are supposed to make your entrée in the public cloud. On prem stalwarts cite this requirement on a regular basis demanding a plan as detailed as the inroad itself. For a while I figured this was just an excuse from the luddites to slow down progress, so it puzzled me when I heard this from people whose opinion I do care about. The bug buzzed in my ear for months: what if they are right and this road indeed leads to trouble? What if Mount Rushmore is not so pretty when viewed from the other side? To settle this I typed in vendor lock-in cloud computing in Google and Bing to learn. Most answers were either sponsored by cloud vendors or by firms like Cloudflare of Red Hat (Cast AI, VMware, Wasabi etc.) whose real objective was to convince you that you can avoid this trouble with their assistance (that is jumping in their trap instead of Amazon’s or Microsoft’s.) Some were thoughtless like the one from a HDD manufacturer arguing that cloud lock-in would lead to the lack of scalability (really?), some were lazy enough to copy entire sections (even the drawings) from each other. Okay, this is useless, so let’s dig deeper. The rest of this article is the result of this digging and the outcome of consulting with Lydia Leong from Gartner, peppered with my longing to computer history. Spoiler alert: when was the last time you listened to music on a CD player, or to phrase it differently: do you have an exit strategy for your Spotify (Netflix etc.) subscription, that is you purchase an on prem copy of each song or movie you like? If you don’t, then read on!
A few definitions:
Disaster Recovery Plan ≠ Exit Strategy ≠ Exit plan ≠ Testing the Exit plan
- A Disaster Recovery (DR) plan is part of the Business Continuity Plan (BCP). It has nothing to do with an exit. When somebody asks you to execute a cloud exit in days, that is a DR situation, not an exit. For this reason, I omitted situations when the Cloud Service provider (CSP) becomes insolvent overnight and is forced to shut down its entire service. I also left out cases like a nuclear bomb wiping out all DC-s in multiple regions (not just availability zones) of a cloud provider. In this case we have an existential problem way beyond a service disruption. (and yes, Putin is moving these deadly toys into Belarus as we speak…)
- An Exit Strategy defines the triggers when your Firm will want to or will have to get out of a Cloud agreement. Players in this decision are the Business owners, the IT leadership, Procurement, Legal and the IT architects.
- An Exit plan is the series of steps -and the players with their specific roles and responsibilities -that are triggered by events defined in the Exit Strategy. It covers technology and business process related changes; thus, not an IT only problem at all.
- Two types of cloud exit: moving an application elsewhere or leaving the platform altogether are two different games. Depending on the players involved in the conflict triggering the exit you might face any of these.
- Testing the Exit plan: walking the talk and moving a workload from the original cloud location to A: another cloud provider or B: back to on prem.
Concentration risk is the risk associated with dependence on a single supplier for multiple business capabilities. This is applicable to on prem IT environments as well. Imagine that you have to move away overnight from the RDBMS provider having a few thousand DB-s and a few hundred thousand lines of PL/SQL code holding the bulk of the business logic of your core applications. The same goes for the runtimes and the language itself from the same provider. You bet; you are on the hook. Some smart consultant coined a derivative called Cloud concentration risk. This is the risk associated with dependence on a particular cloud provider for multiple business capabilities, such that a single failure can result in a disruption to multiple aspects of the business. It’s on prem sibling is a major outage in your primary data center.
The triggers: Who can say no?
There are five possible actors in any cloud exit: the service provider and the consumer, the buyer’s regulator and two nation states (the vendor’s and the consumer’s).
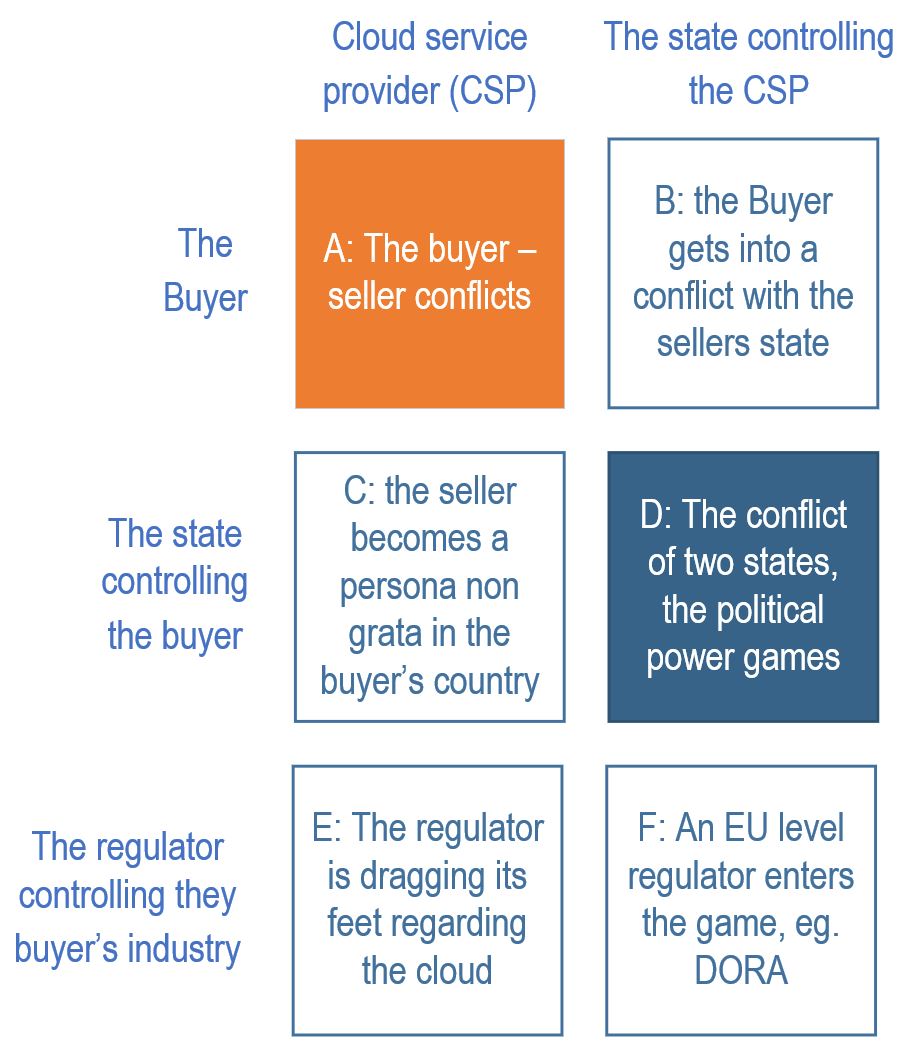
- Buyer-seller conflicts: this is in scope for this post.
- Buyer in conflict with the seller’s state –this is a weird idea for any firm (at least in my home country) to get into a fight with the US government, so I risk to skip this.
- Seller in conflict with the buyer’s state – not impossible, (eg. East India Company vs. China, but this one too ended up as type D.)
- The conflict between two states – the USA banned the sale of key IT technologies (on prem as well) to Russia after their attack on Ukraine. FTR: it was not allowed to transfer any personal data outside of the Russian Federation anyway, therefore US cloud providers were a no go before the war.
- Whoever claims that the (HUN) regulator said no to the public cloud, pls. show me the actual paragraph in their guidance to prove it.
The types of conflicts between the seller and the buyer (type A):
| When the seller says no | When the buyer says no |
|
|
A word on innovation and its relation to vendor lock-in
Repeat after me: Innovation comes from differentiation. Maximizing the value of cloud adoption requires exploiting the provider’s capabilities, thus increasing lock-in. The flip side: The greater your need for portability, the more you are likely to sacrifice some of the benefits of cloud services —and the greater the complexity and cost. The deeper you walk into the cloud forest, the more likely you will stay there for a long time.
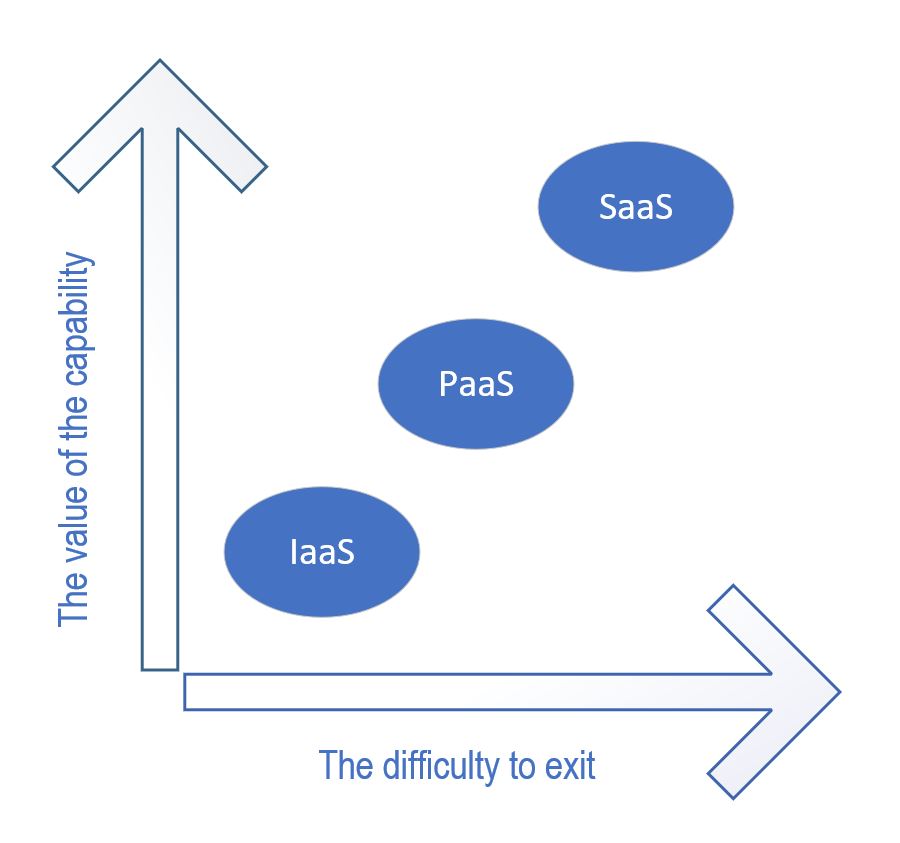
I met an IT executive who thought that the cloud was nothing more than a 3rd data center owned by someone else. For this reason, he demanded complete symmetry, that is using components in the cloud only if they had an on prem counterpart. (read IaaS) To be fair, he was right from an exit viewpoint, but ignored the efforts of all major cloud providers in the last 5+ years, that is PaaS. This is where most of their R&D spend went, probably beside IT Security. Bottom line: the more value you take out from the cloud the more difficult it becomes to exit from it. In case of SaaS this is simply a redo exercise, same cost, same time.
To illustrate the innovation story let me use an old example, the 360 series mainframes from IBM. This was the first modular, general-purpose, upgradeable series of mainframes with the same OS for all models – that is running the same application without modifications, introduced the micro-coded CPUs, the 8 bit bytes (today it sounds funny, but there was financial pressure to use 6 bit bytes, since memory was expensive), the EBCDIC character set, a new floating point architecture, a nine track magnetic tape drive, backward SW compatibility with older IBM products, all in all a tremendous amount of innovation. It cost half of the development of the atomic bomb, the development time was way over the original plans, but within 15 years it drove the seven dwarfs out of the computer business (7 dwarfs = Burroughs, Sperry Rand, Control Data, Honeywell, General Electric, RCA and NCR) Was it a true vendor lock-in? You bet it was: It was compatible only with itself, but it was the best of its time so much that this was the origin of the saying “Nobody ever gets fired for buying IBM”. And guess what, this was the seed of the antitrust law suit that almost chopped IBM into pieces. If you are into computer history, check out the book written by the Fred Brooks (the PM of the development, working in tandem with Gene Amdahl, the lead architect) titled the Mythical Man-month.
A word on R&D budgets: If you check out the annual reports of the hyperscale providers and their traditional on prem counterparts you will find telling numbers. In a nutshell: there is an ongoing shift of profits from the incumbents to the largest cloud players. (eg. Amazon is now the largest database vendor, surpassing Oracle.) Their net earnings are manyfold compared to the traditional HW and on prem SW providers like HP or even IBM. If we assume that each R&D dollar has similar financial impact at all major players, this is fair to say that the hyperscale providers are on a growth trajectory (because their cloud R&D is larger and is funded by their cloud business, not by a separate cash cow) while their on prem counterparts will face tough times within 5-6 years. This is why IBM paid 34 billion USD for Red Hat. This move was triggered by the realization that they lost the cloud war. The real thing is that the war is no longer in the cloud area, this is over, the battle moved to the AI territory with even bigger stakes.
Busting myths
There are no solutions that eliminate lock-in. Vendors just want you to become locked into their solution instead of someone else’s. Think about it: if Vendor A’s service is 100% compatible with Vendor B’s service, then the ONLY differentiating factor will be the price. This would lead to a cost war to the bottom, that would force both vendors to cut back their R&D budgets. At the end they (and you) would end up with commodities where the only differentiator is the price, read: ZERO innovation. There are competing forces at work here: the appetite for innovation in the buyer’s side intertwined with the need to differentiation on the vendor’s side plus the demand for freedom to escape those providers whose innovation stream has dried up. Since I used a mainframe example for ground breaking innovation I have to mention other mainframe providers whose only excuse to exist is that one’s primary application runs on their iron and this is very-very expensive to move away, and they know it. On the other hand, you have a choice which vendor’s lock-in you want to avoid and which we prefer in order to avoid the other one.
A cloud exit plan does not provide any reduction in your availability risk. The period when the cloud service is unavailable is way shorter than your ability to execute any exit plan. You need to address this in your DR plans WITHIN the given cloud itself. (nope, cloud to cloud exit is not a panacea for resiliency, see below.)
Multi-cloud is not a solution for cloud resiliency since it is difficult and expensive to implement. I had a chat with a senior IT executive a few weeks ago. When we got to this issue, he figured he would ask his teams to build a software application targeted to public cloud to be either portable, OR to develop two versions of the same SW in the same time for the two hyperscale providers. I think both of these ideas are unpractical: If you build a software that uses the common subset of the functionalities you will throw away the bulk of innovation coming from any of these providers. If you build for both in the same time you will ruin the business case and the time expectations of the business, ie. I would rather not even start this endeavor.
One more word on multi-cloud: this will eventually happen to most large enterprises, either by choice or by accident when a software vendor is picked by the business who happens to use the other CSP. This will put an additional training burden on the internal IT departments of large enterprises, let alone cranking up the price tags for those folks literate in both technologies. (I always talk about two hyperscale providers instead of three, no intention to disregard GCP, this is just simpler to express myself this way.)
If your exit is triggered by a change either from the seller or the buyer’s regulator, this will rule out any cloud-to-cloud exit, because a regulatory change (for the record a state decree) will render all of your target exit providers unviable. (eg. Russia, unless you consider Alibaba…)
Your ability to execute an exit from your cloud provider does not improve your negotiation position, since cloud exits are complicated and costly and the CSP knows that the cost of a cloud switch will exceed any price advantages gained through the switch. To be fair, this is no longer a money printing machine like it used to be in the on prem - perpetual license days. This is a service with actual cost of building and running astonishingly large data centers all over the world, let alone their electricity and communication costs. Do not dream about 50% discounts. If you check out the annual reports of key cloud providers, their profitability is in the range of 30-35%. If you consider their buying power and operational efficiency, chances are 1 kilogram CPU from them cost less than 1 kilogram CPU in your DC. (Leaving on the lights when not needed is a different problem, but this is finops, a subject for another post.)
Containers do not eliminate cloud lock-in: Theory (and Kubernetes providers) say that putting applications in containers will solve the cloud lock-in problem with no drawbacks. Tag line: “Once an application is in a container, it is easy and cheap to move it between cloud providers, or between cloud and on-premises environments.” On the one hand containers and microservices became the hallmarks of cloud native development, and they do ease some aspects of portability. On the other hand, they do not address most of the underlying causes of lock-in. Container management platforms are one out of the hundreds of PaaS services available from any of the top cloud service providers. Replacing this with a 3rd party component will have no effect on the dozens of PaaS components also required to run a modern application.
Regulators DO NOT want the whole exit plan executed before you go to the cloud with your app. They will be satisfied with plans that can be executed over a reasonable period of time (such as two years), without requiring that you demonstrate your ability to actually do an exit. The effort required to test an exit scenario is comparable to the effort of moving to the cloud itself. Unless the regulator wants to ruin the whole business case to move to the cloud, they will not demand it. The good news, they heard of FinTech and BigTech and know that if they overdo their “no cloud please” thingy, they hurt the entire industry rather than protecting it.
Your options
- Minimize lock-in as much as possible: Cloud IaaS providers are treated like infrastructure resource commodities, and higher-level functionality is avoided wherever possible. This requires a very high level of skills in the IT team and significant engineering effort, time and risk since you assemble your car from thousands of tiny parts coming from several manufacturers. Not recommended, since you lose the innovation and the developer efficiency gains brought by the PaaS components. You throw the baby out with the bath water.
- Use overlays to minimize cloud IaaS provider lock-in: You can try to minimize lock-in to the cloud IaaS provider, by overlaying the provider’s resources with third-party solutions that are portable across multiple environments. This results in a high degree of lock-in to the overlay solutions and vendors, as well as the ecosystem around those solutions. The cloud IaaS providers may be treated like infrastructure resource commodities, thus losing the innovation brought by the cloud provider.
- Be loyal to a single ecosystem: you choose one vendor’s ecosystem to base your strategy on it, accepting the notion that you will have long-term dependency upon that vendor. Innovation, ease of integration and speed of delivery are the highest priorities. You accept that you will become highly dependent on this cloud provider over the long run, and must invest in building a strong, trusted relationship with that vendor. Resiliency is handled within the provider’s ecosystem, using cloud native tools.
- Be loyal to more ecosystems: You build capabilities on two or more providers, but not for resilience purposes, but to maintain the balance when negotiating with mega players. You manage cloud concentration risk primarily through a multi-cloud workload placement strategy, rather than through a cloud exit strategy. The two cloud you bet on are likely to be two out of the three hyperscale players.
The final word: You do need to be prepared to exit your cloud provider but not for the reasons usually quoted by most articles on the web. The real dilemma is to pick the right provider and to maintain the relationship as long as it provides competitive advantage to your firm. A cloud exit is a complicated and very long journey. Planning an exit in advance will help you shorten the time to a successful execution, thus jumping from a limping horse to better one in time. To paraphrase Oliver Cromwell "Trust in your cloud provider but keep your powder dry!"
As always I will appreciate any feedback on this post.
Sources used for this paper:
- https://www.ebf.eu/wp-content/uploads/2020/06/EBF-Cloud-Banking-Forum_Cloud-exit-strategy-testing-of-exit-plans.pdf
- https://www.mnb.hu/letoltes/4-2019-felho.pdf
- The IBM System/360 and the Third Generation of Computing --1964 | History of Computer Communications
- https://www.digital-operational-resilience-act.com/
- https://www.visualcapitalist.com/cp/big-tech-revenue-profit-by-company/
- https://www.statista.com/statistics/264920/hewlett-packards-net-earnings-since-1998/
- Exit Planning for MS Cloud Services | LinkedIn
- Cloud exit planning guidelines for financial services institutions - Microsoft Industry Blogs
- Hybrid and multicloud strategies for financial services organizations | Azure Blog and Updates | Microsoft Azure
- NIST 800-53 vs ISO 27002 vs NIST CSF (complianceforge.com)
- Microsoft - Enterprise Business Continuity Management (EBCM) Program
- Cloud exit strategy – testing of exit plans (EBF)
- Recommendations on outsourcing to cloud service providers | European Banking Authority (europa.eu)
- Guidelines on outsourcing arrangements | European Banking Authority (europa.eu)
- MNB - Frequently asked questions concerning the use of cloud services (FAQ)P
- AZ MNB 4/2019. számú ajánlása a közösségi és publikus felhőszolgáltatások igénybevételéről
- MNB 7/2020. számú ajánlása a külső szolgáltatók igénybevételéről
- How to Manage Concentration Risk in Public Cloud Services - ID G00762620
- The Cocktail Napkin Cloud Strategy: Efficiently Align Your Organization Around Key Principles -ID G00772809